yolov5+csl旋转目标检测代码解析——总结篇
本篇主要记录学习yolov5+csl旋转目标检测的原理,对前几篇文章作一个总结,添加一些细节。参考知乎 略略略 https://zhuanlan.zhihu.com/p/358441134; yangxue https://zhuanlan.zhihu.com/p/111493759
一、训练部分
1.数据加载
加载数据的主要过程都在create_dataloader这个方法里。
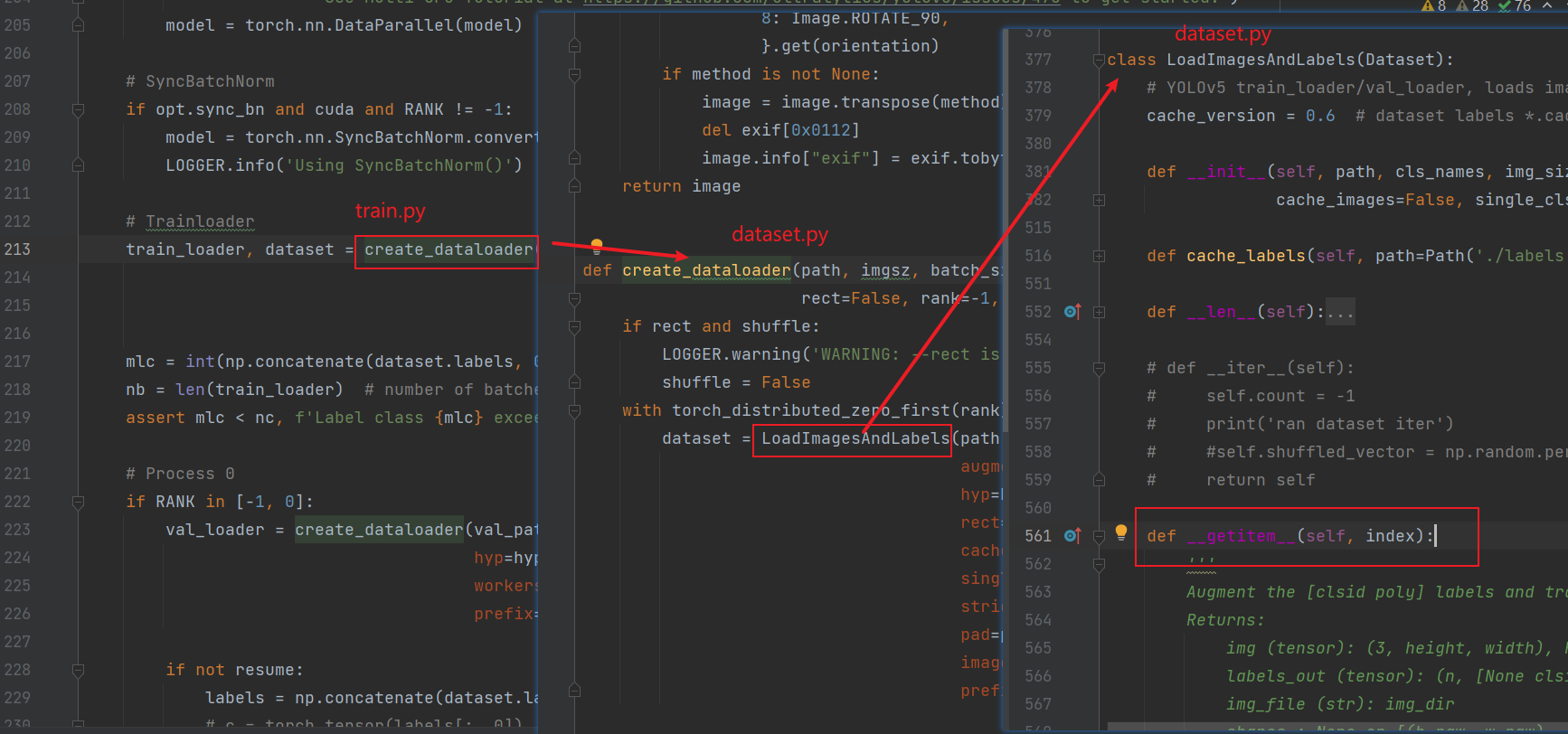
下面是该方法的返回值:
return loader(dataset,
batch_size=batch_size,
shuffle=shuffle and sampler is None,
num_workers=nw,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn), dataset
需要注意的是,这里返回的dataset是原始数据(与我们的label基本一致,clsid换一下),但是在下面遍历这里所取得的train_loader成员的时候会调用 LoadImagesAndLabels这个类的专有函数getitem__(self, index),这里重写了这个方法,使得返回将原先[x1, y1, x2, y2, x3, y3, x4, y4]格式标签转换成了旋转目标检测的长边表示法,同时作了一些数据增强(中途print一下label会发现标签在变成长边表示法之前改变了),另一方面这里的img输出是经典的[3 , h, w],RGB格式。
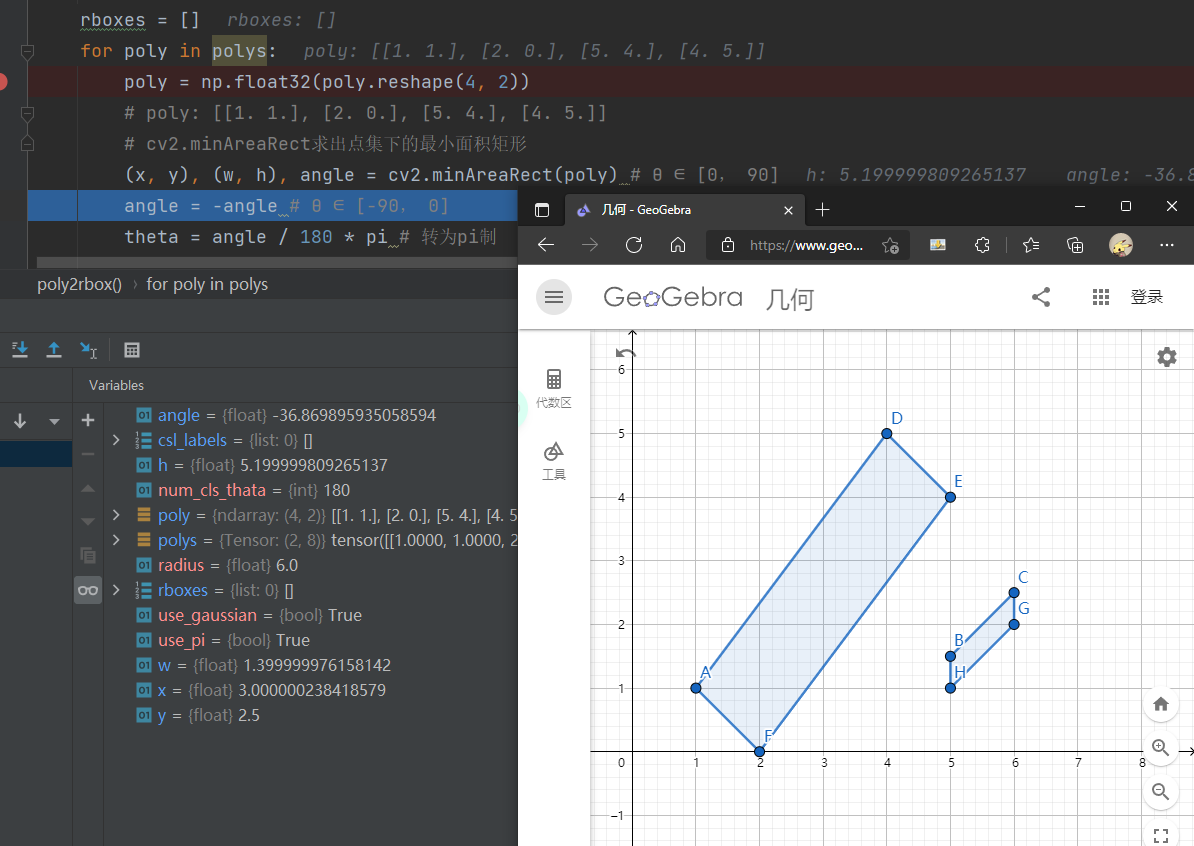
其他有一个小地方要注意一下,在poly2rbox这个方法中,根据四点坐标计算中心点坐标以及长短边角度的函数用的是cv2.minAreaRect(poly) ,这个方法原意是求任意个数的点集所围成的最小矩形(计算量还是有的),在转换poly表示法到长边表示法的过程中似乎与我所理解的有所不同(见下图),我的理解长边很明显是5. 其实这不是个标准矩形,长边表示法是标准矩形。
def __getitem__(self, index):
'''
Augment the [clsid poly] labels and trans label format to rbox.
Returns:
img (tensor): (3, height, width), RGB
labels_out (tensor): (n, [None clsid cx cy l s theta gaussian_θ_labels]) θ∈[-pi/2, pi/2)
img_file (str): img_dir
shapes : None or [(h_raw, w_raw), (hw_ratios, wh_paddings)], for COCO mAP rescaling
'''
2.推理pred
首先train.py这里改变图片尺寸(/255)作归一化,给tensor处理,同时改为浮点类型,shape不变

这里把图片(图片shape[b, 3, height, width], RGB)喂给网络,
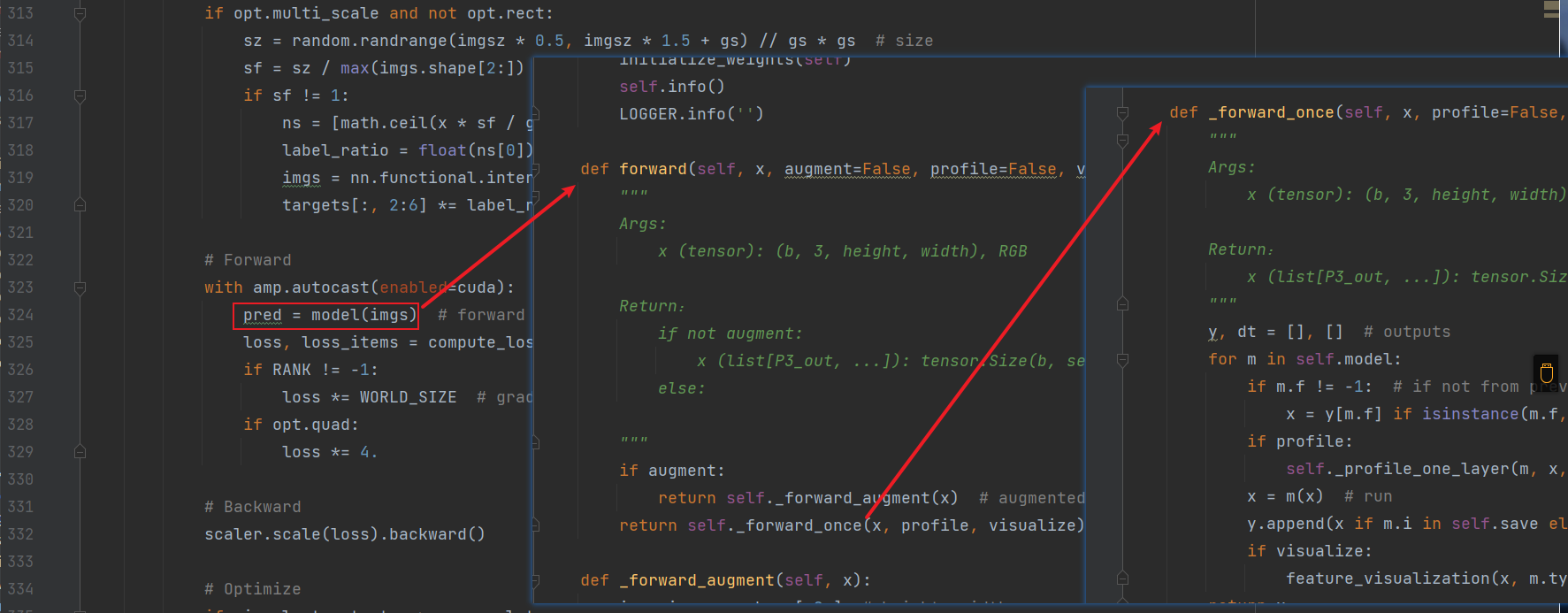
然后在forward里迭代网络的各个层(卷积、C3等)
经过第一层卷积:
Conv(
(conv): Conv2d(3, 48, kernel_size=(6, 6), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
之后x的shape变成如图(2, 48, 512,512)
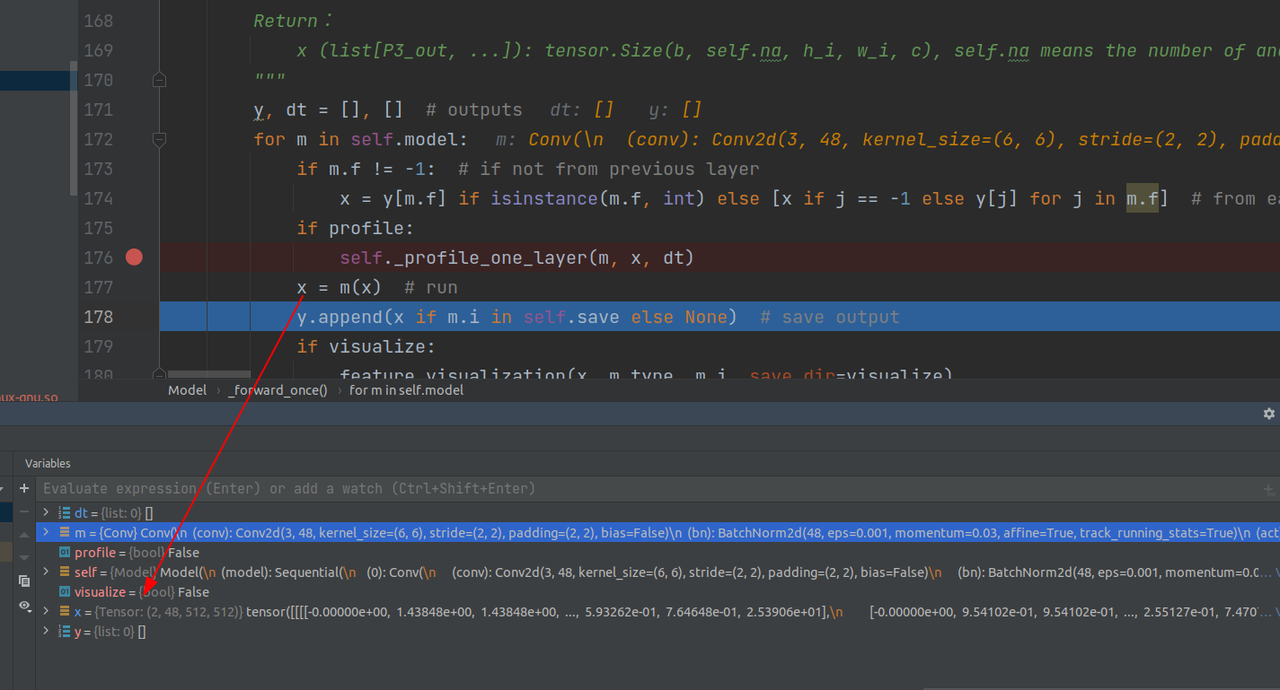
第二层网络结构:经过第二层网络之后的x的shape:(2, 96, 256, 256)
Conv(
(conv): Conv2d(48, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
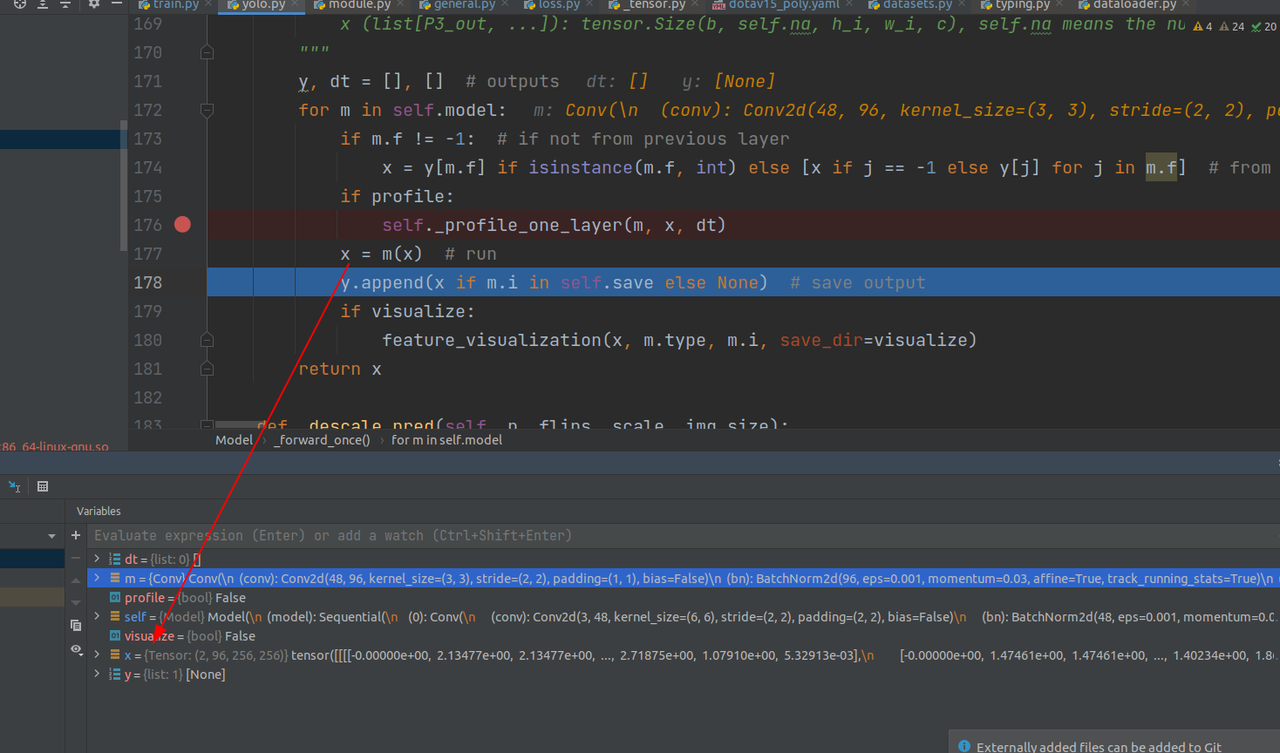
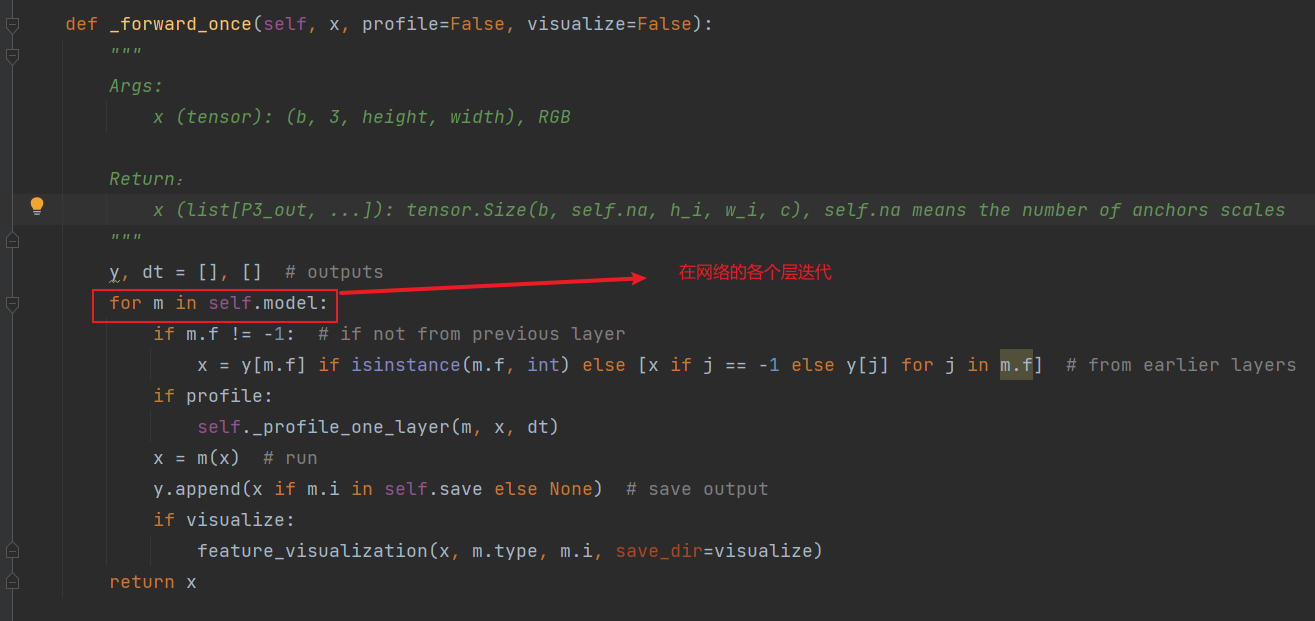
依此类推,需要注意的是在第12层concat层,将当前层(即上一层输出的x)和m.f参数指定的之前保存的某一层结合作list
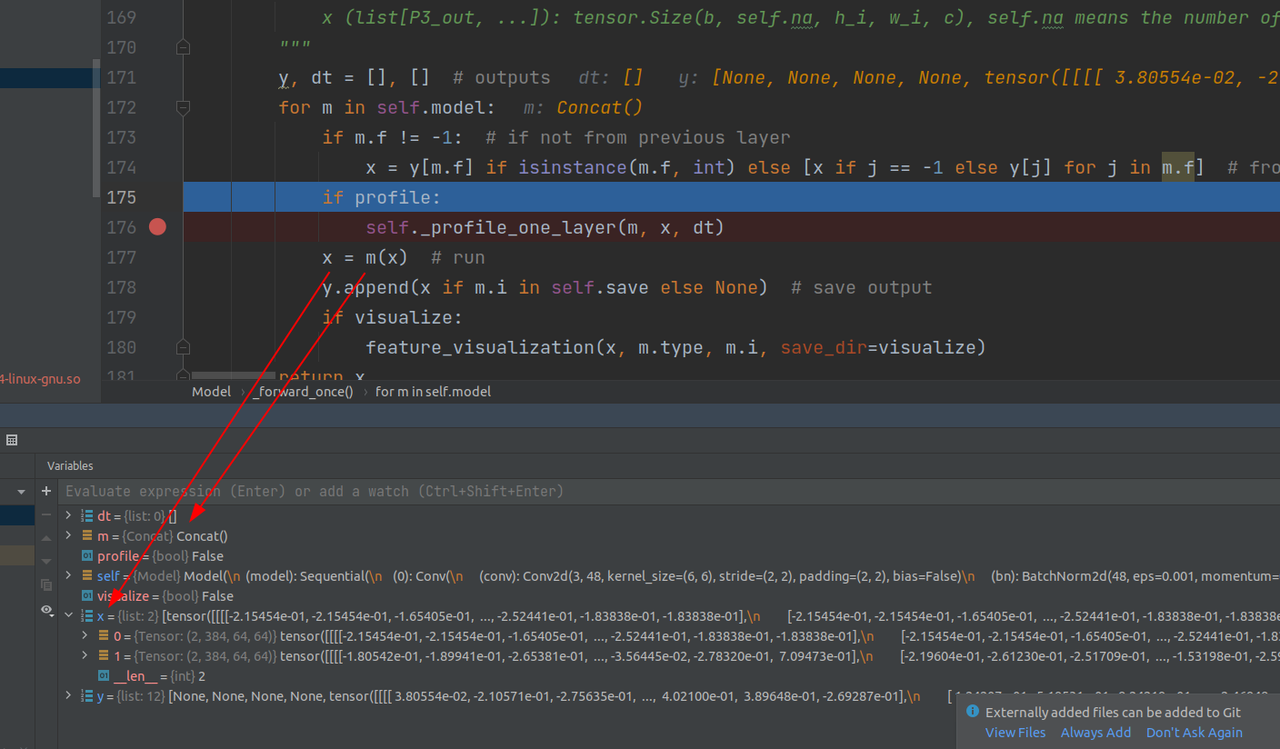
在第16层的时候同样,将当前层和m.f参数指定的之前保存的某一层结合作list,下面还有concat层,不作记录
共25层(整体网络结构见上一篇,这里不再给出),下面是最后一层detect层之前,可以看到,过程中根据self.save参数保存了部分层的输出,并且根据m.f参数,指定当前层的输入是单一的上一层输出还是和之前层组成的list
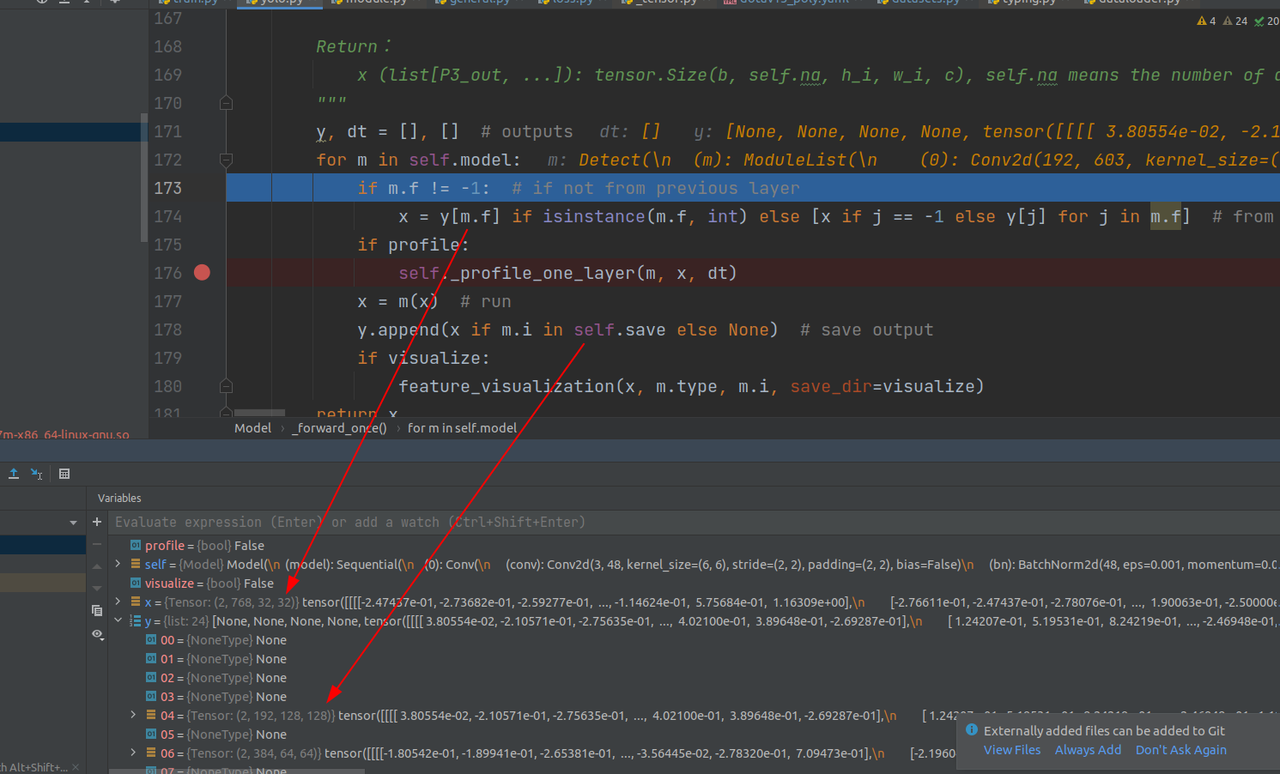
比如detect层的m.f参数是如下:
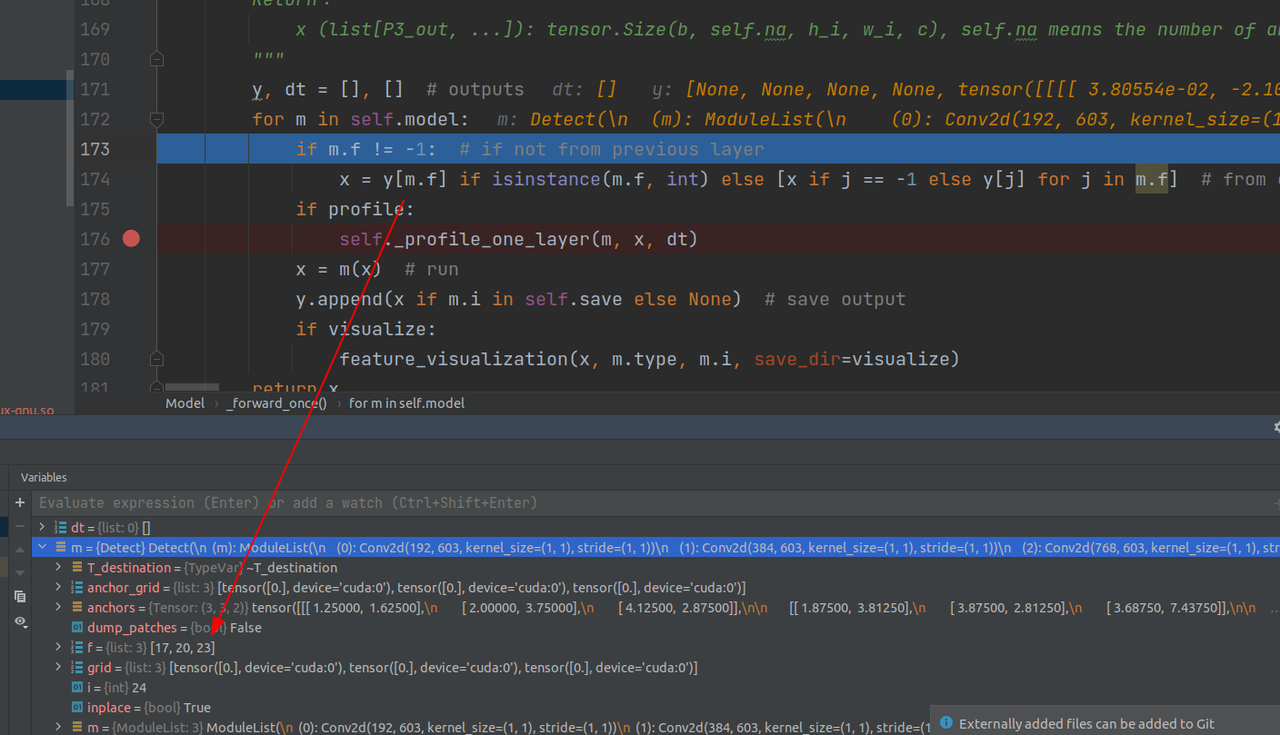
则意味着要把y中这几个层的输出联合成list
detect层内容:
Detect(
(m): ModuleList(
(0): Conv2d(192, 603, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(384, 603, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(768, 603, kernel_size=(1, 1), stride=(1, 1))
)
)
分别对三个尺度的tensor作卷积,经过detect层之后三个尺度的输出:
2.1 detect层细节处理
下面是detect层处理的一些细节:
首先进入forward,按lawyer(3层)操作,经过第一次卷积之后x[0]变成如图:
这里把x[i]进行重组(我的理解相当于一个线性层,但不完全一样):
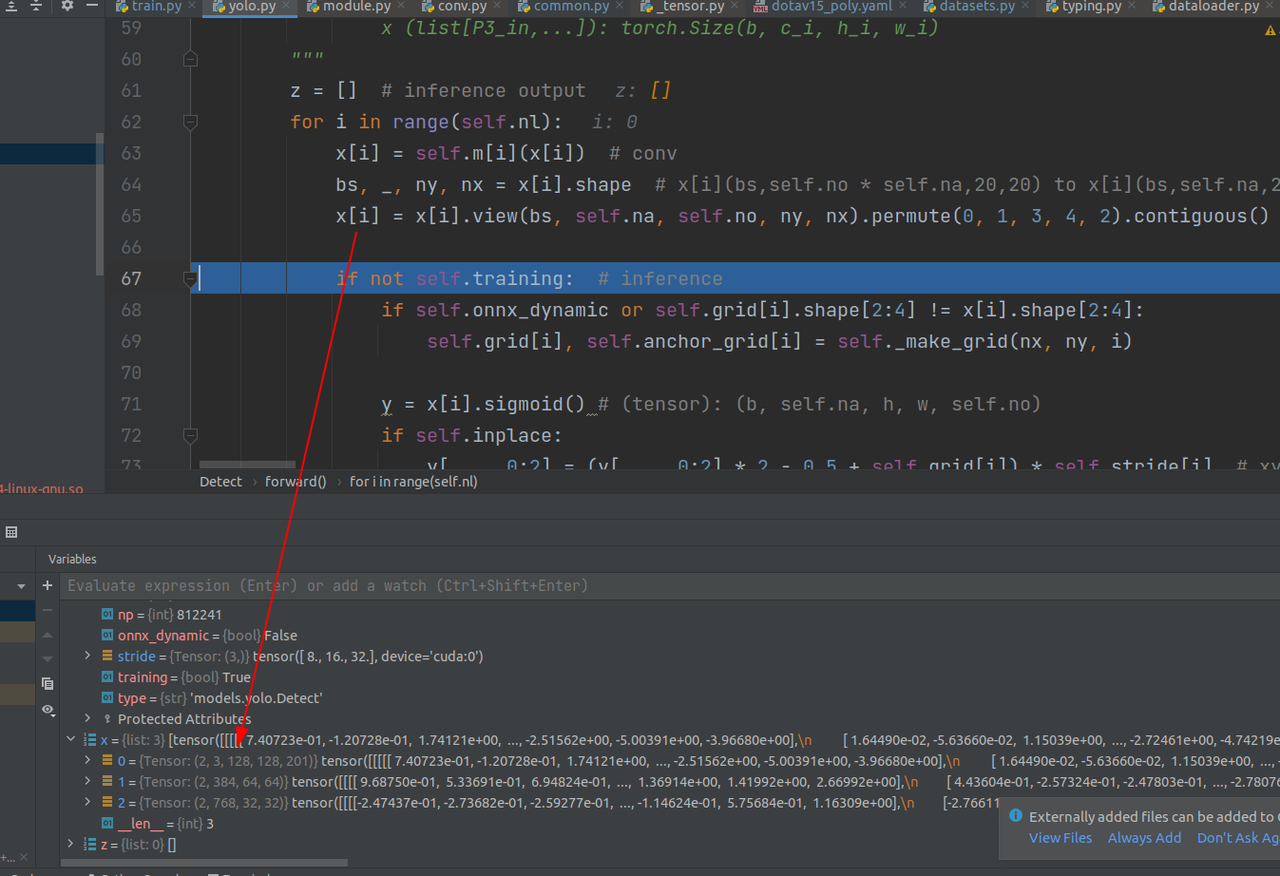
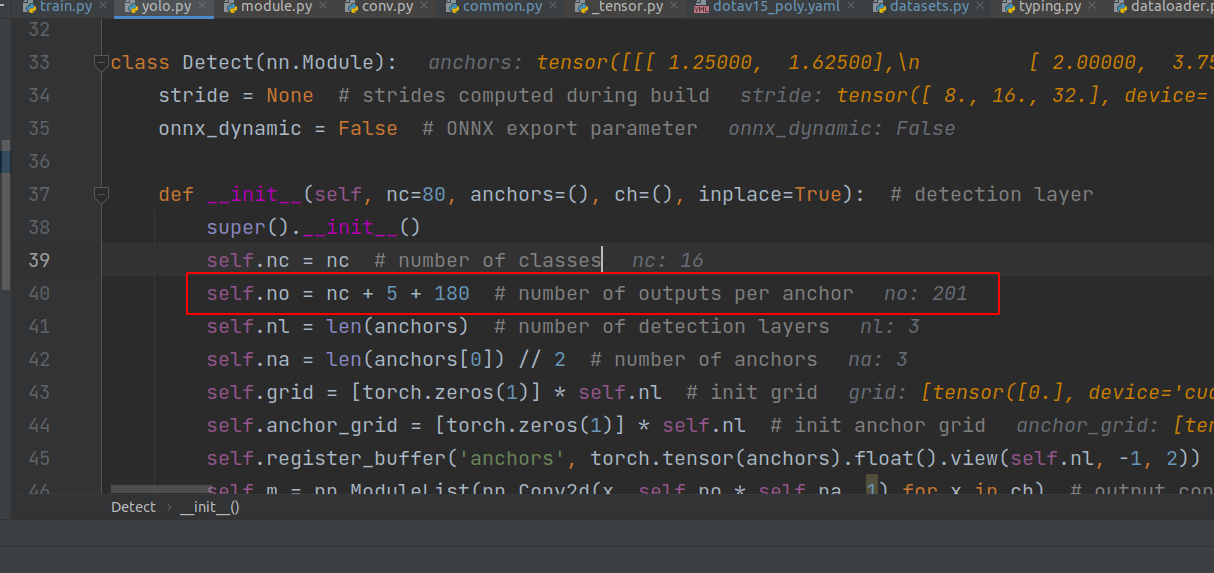
201是self.no参数,在detect类中定义(如下图),代表着[16个类别,cx,cy,l,s,theta,180个gaussian_theta_labels],值得注意的是,这201个参数是相对于一个anchor来说的。这里2是bz,3是每一个grid负责的anchor数量,即一个grid产生3个anchor,然后每一张图片,按3个尺度,分成128×128,64×64,32×32个grid。
3.损失计算
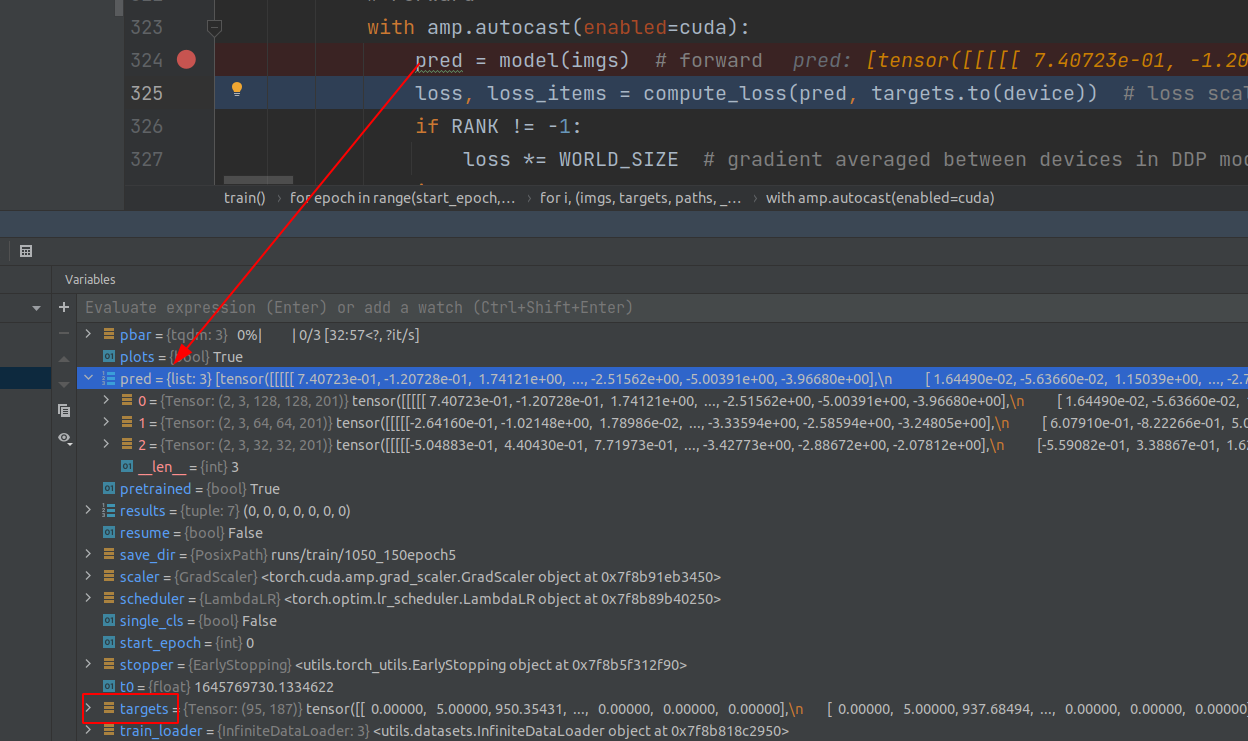
送给loss时pred(三个尺度的输出,yolov5特点)和target的格式:
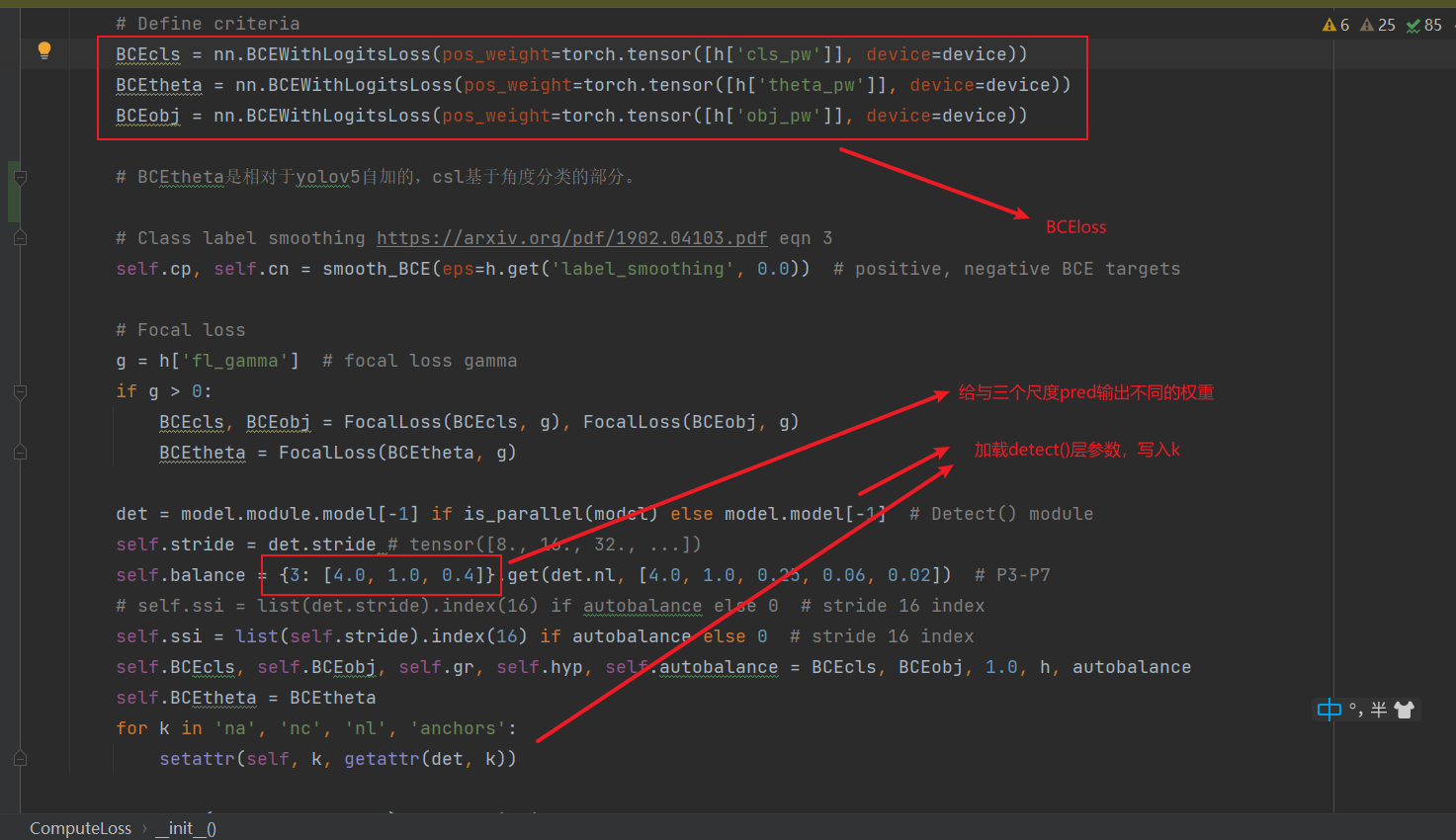
computer_loss初始化时的一些设置
下面是调用computer_loss的call方法一部分,重点是最后的build_targets方法
def __call__(self, p, targets): # predictions, targets, model
"""
Args:
p (list[P3_out,...]): torch.Size(b, self.na, h_i, w_i, self.no), self.na means the number of anchors scales
targets (tensor): (n_gt_all_batch, [img_index clsid cx cy l s theta gaussian_θ_labels])
Return:
total_loss * bs (tensor): [1]
torch.cat((lbox, lobj, lcls, ltheta)).detach(): [4]
"""
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
ltheta = torch.zeros(1, device=device)
# tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
tcls, tbox, indices, anchors, tgaussian_theta = self.build_targets(p, targets) # targets
3.1 build_targets方法
def build_targets(self, p, targets):
"""
Args:
p (list[P3_out,...]): torch.Size(b, self.na, h_i, w_i, self.no), self.na means the number of anchors scales
targets (tensor): (n_gt_all_batch, [img_index clsid cx cy l s theta gaussian_θ_labels]) pixel
Return:non-normalized data
tcls (list[P3_out,...]): len=self.na, tensor.size(n_filter2)
tbox (list[P3_out,...]): len=self.na, tensor.size(n_filter2, 4) featuremap pixel
indices (list[P3_out,...]): len=self.na, tensor.size(4, n_filter2) [b, a, gj, gi]
anch (list[P3_out,...]): len=self.na, tensor.size(n_filter2, 2)
tgaussian_theta (list[P3_out,...]): len=self.na, tensor.size(n_filter2, hyp['cls_theta'])
# ttheta (list[P3_out,...]): len=self.na, tensor.size(n_filter2)
"""
这里所做的是先把targets复制3份,并且在每一分的最后一维加上anchor信息,比如第一份最后数字是0,第二份最后数字是2,这也是targets的shape由[95,187]变成[3,95,188]的过程
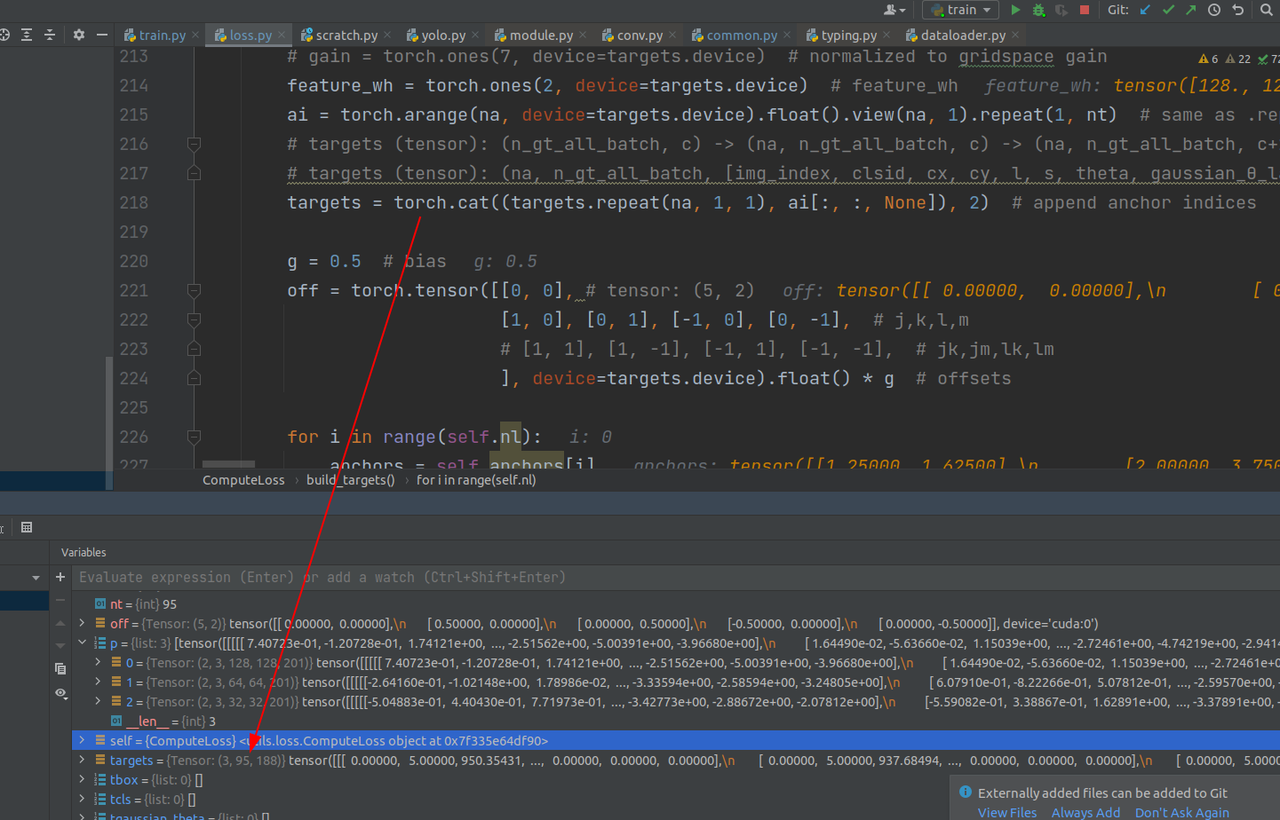
这里提取pred的尺度信息
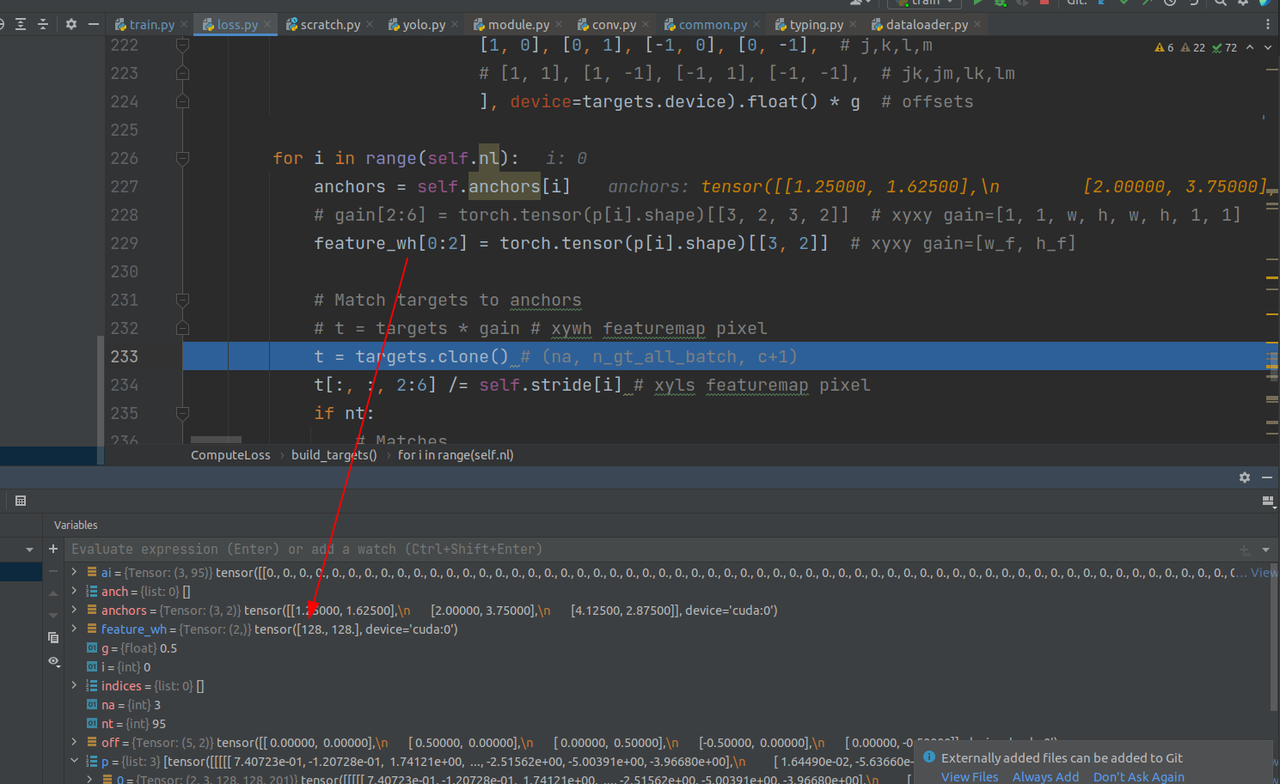
把第三维的2:6列作放缩(坐标信息,cx,cy,l,s)
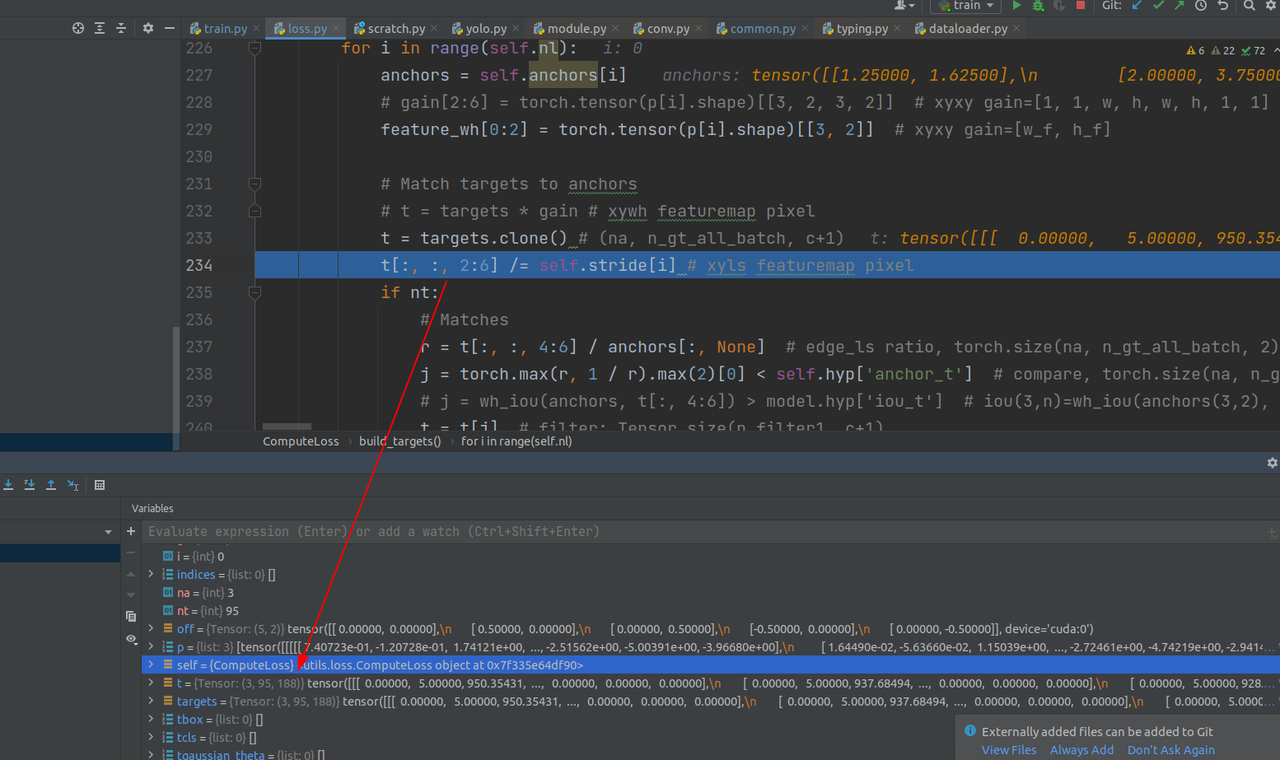
match过滤部分,让某一尺度的anchor预测对应尺度的targets,同时可以避免无限制带来的CIOU计算的梯度爆炸问题。
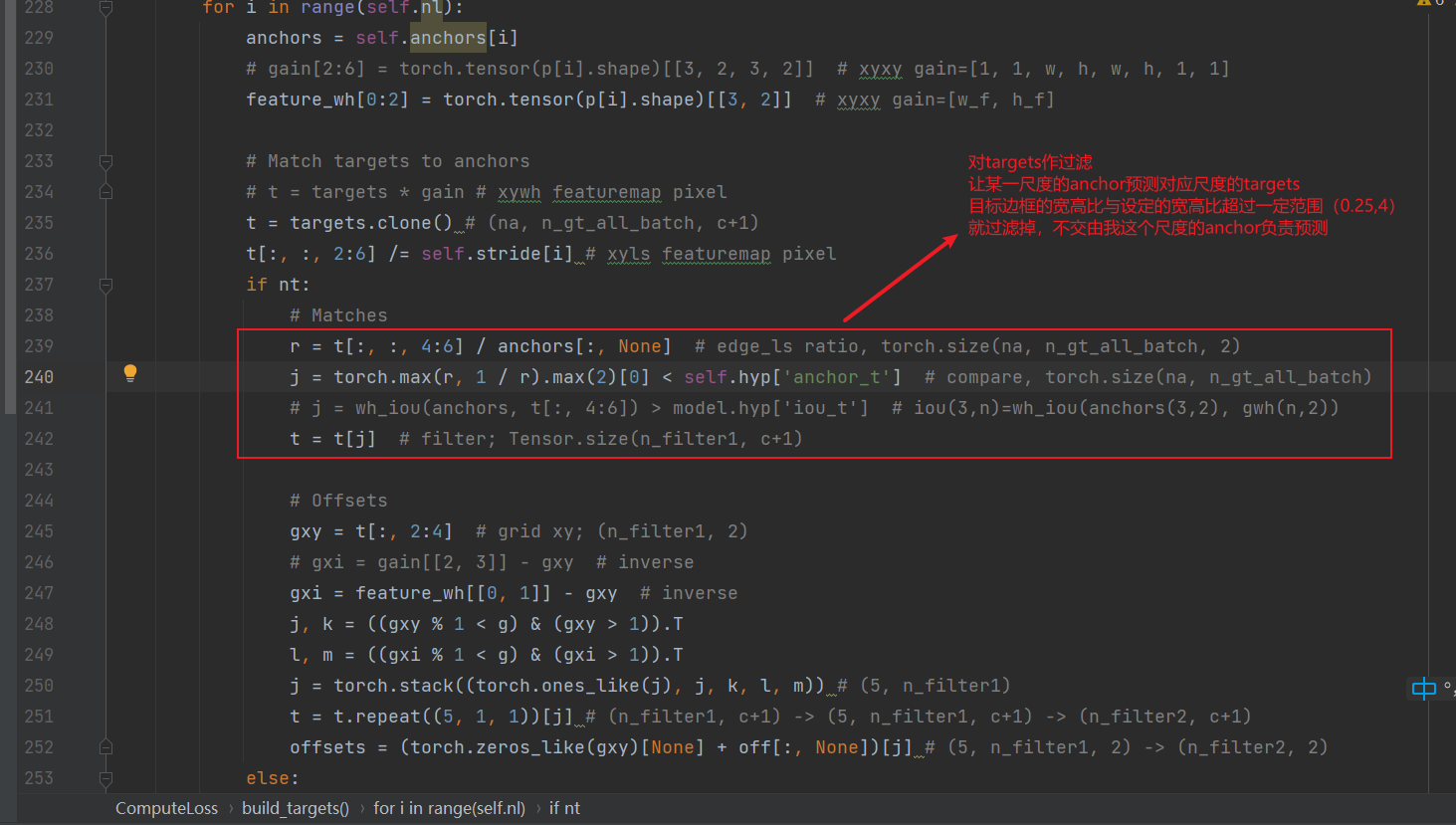
下面这部分是yolov5的正采样部分,细节可以在之前的博客上看到。总之就是把目标中心点那个grid相邻两个grid都标记为正样本,有助于收敛。
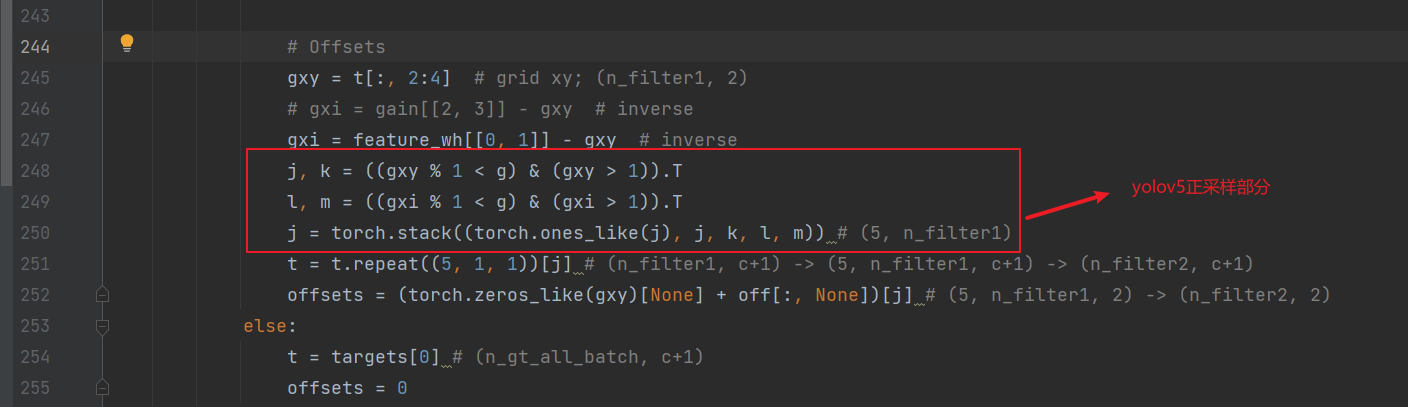
取出targets中预测框中心点以及长短边和180个高斯角度类别信息。需要注意的是,这里只取到了倒数第二列,最后一列是anchor信息(前面提到的加入的0,1,2信息)
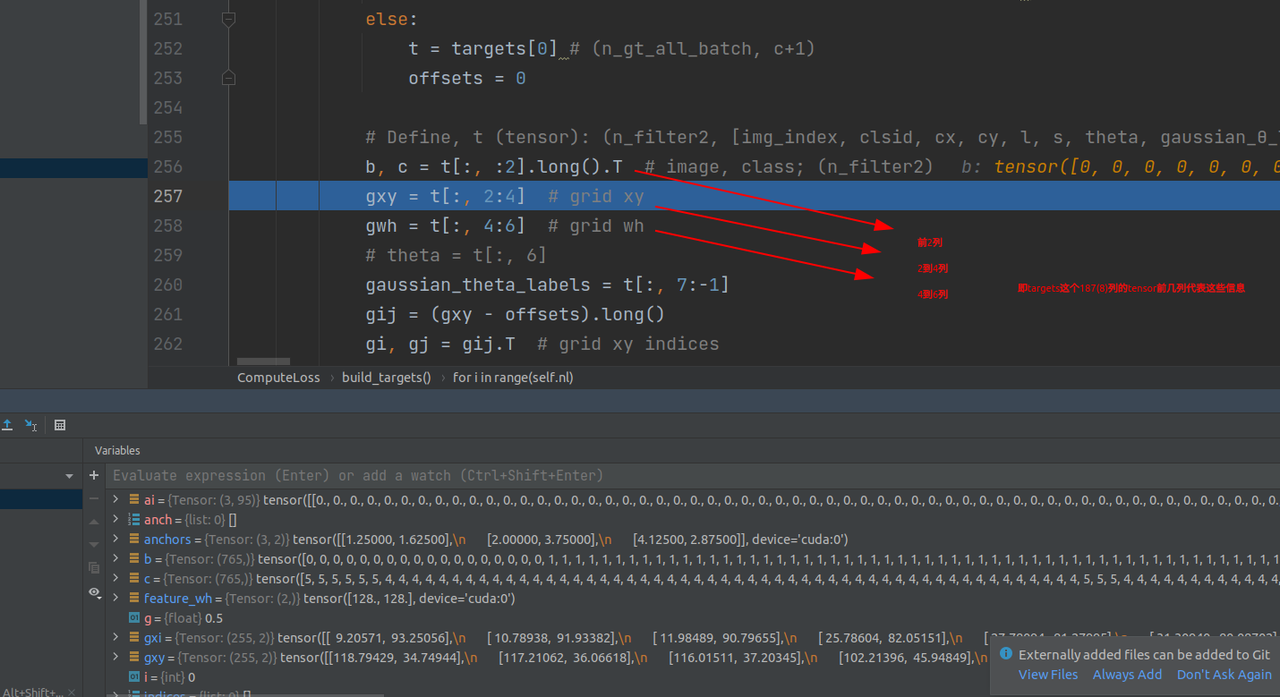
tbox中信息是中心点坐标以及长短边,且是偏移量(减去了grid左下角坐标这种)
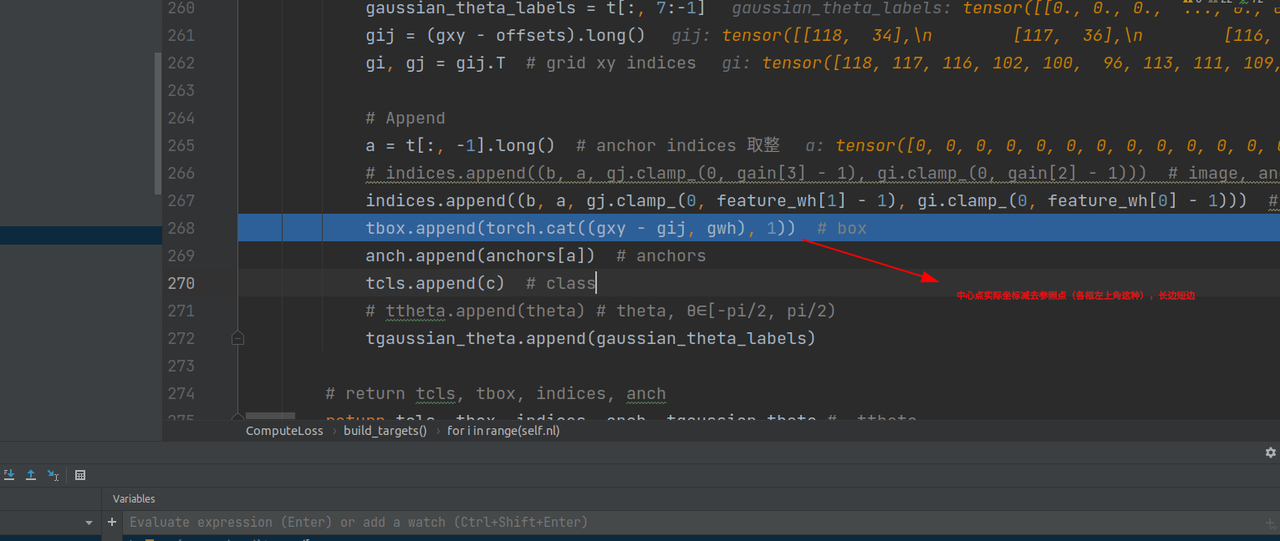
至此build_targets方法就结束了,已经将targets由原始的数据转换成了分开的目标类别,目标框,索引,目标高斯角度类别等。
3.2 计算损失
pred同样在三个尺度上迭代
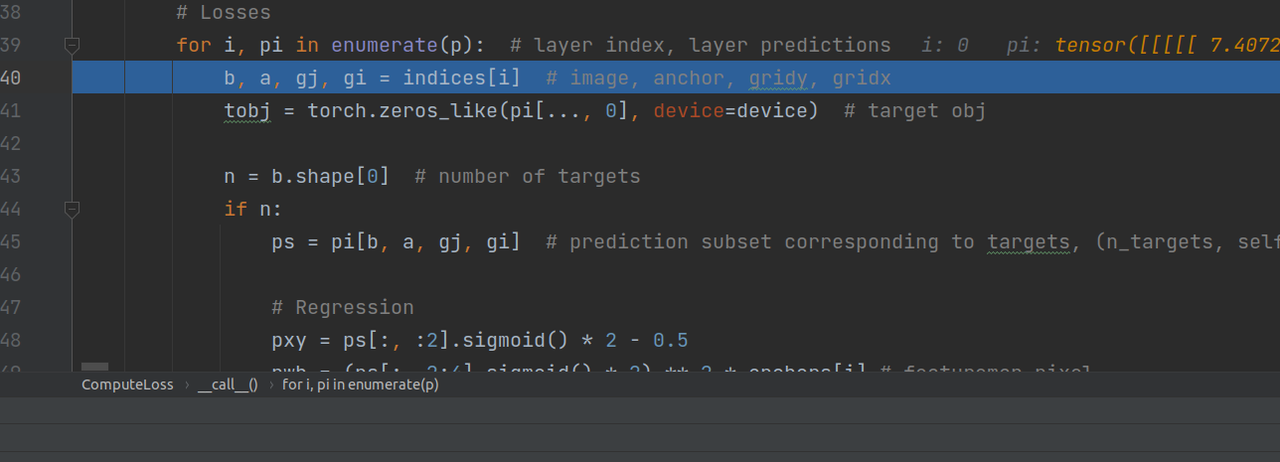
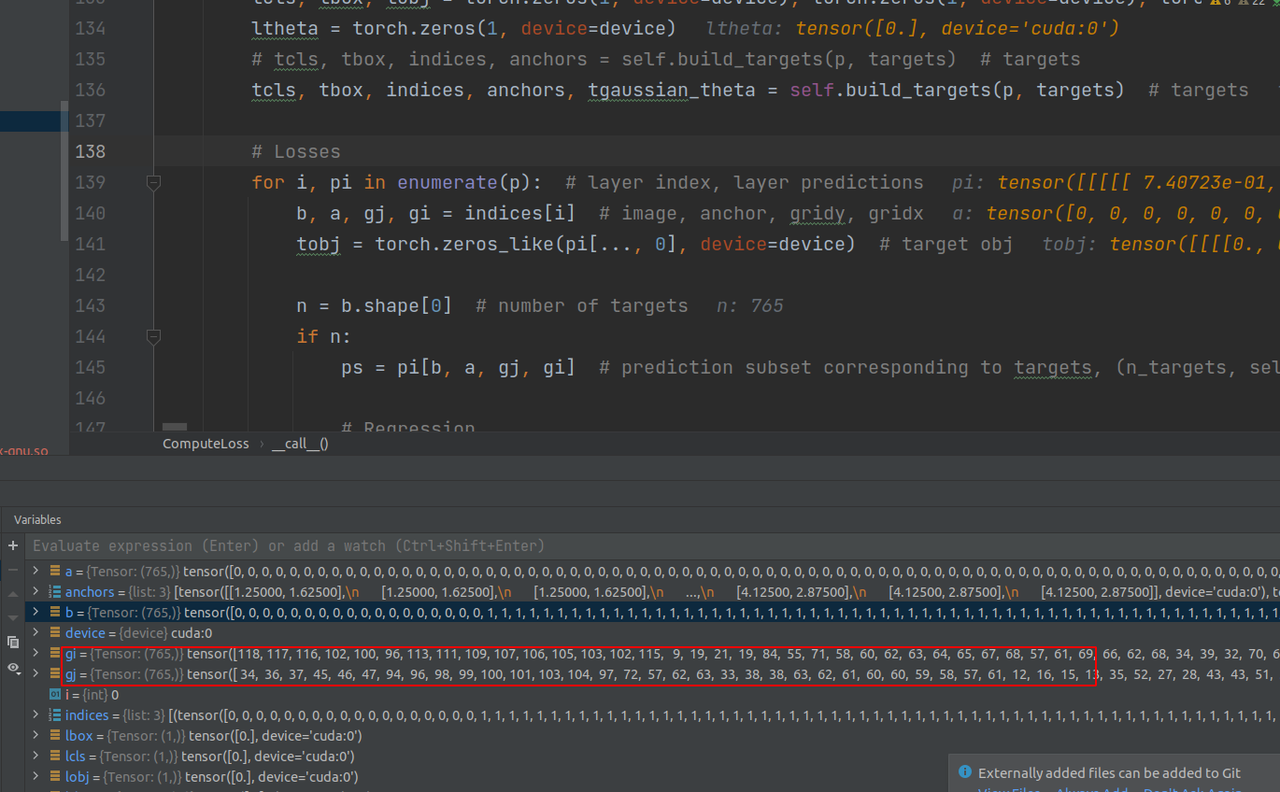
从indices中取出信息,信息包括这765个targets的所属batch,所属anchor,以及在grid中的x,y坐标,然后,把这些信息带入到预测pred中,就能取得这765个anchor的预测信息(长度为201的tensor)。
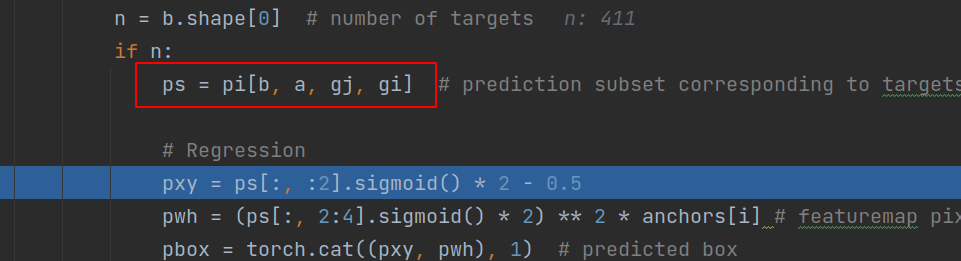
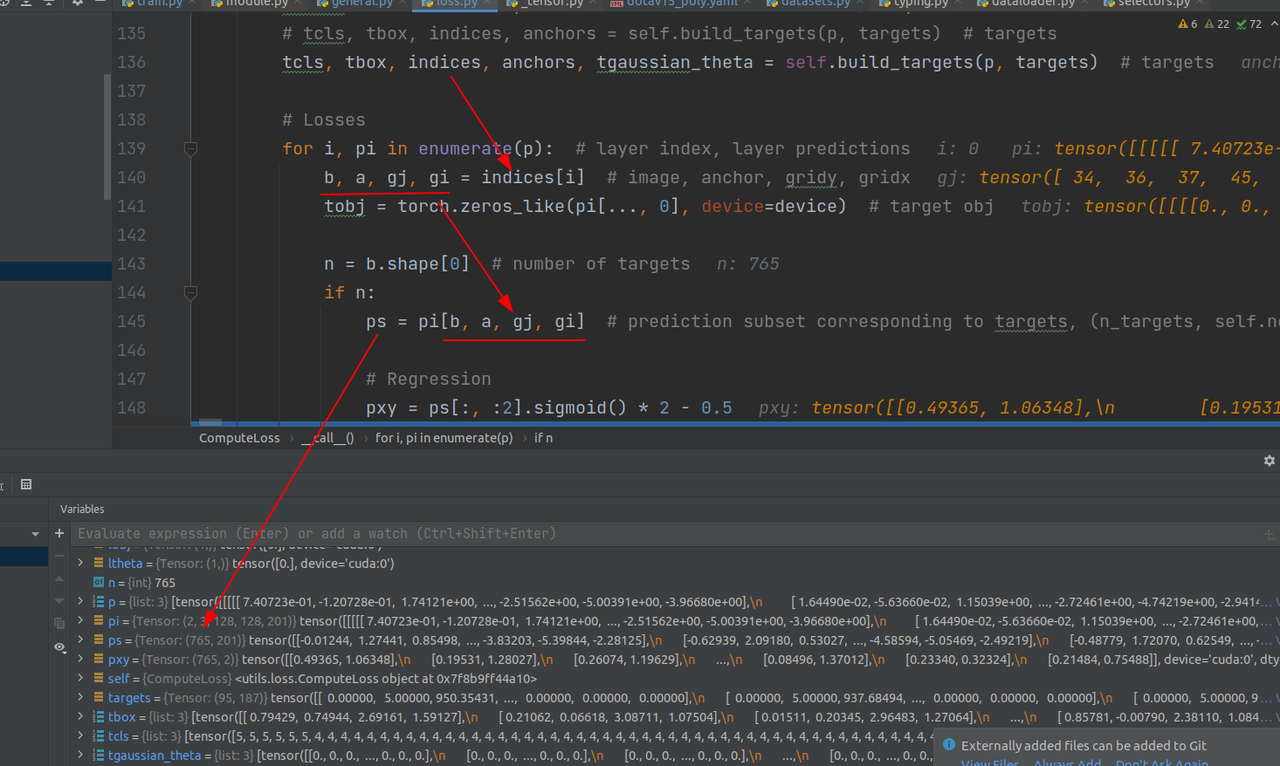
这些gridx,y信息也可以佐证,在128尺度时,这些数据的范围都在128以内,64尺度下的范围也同样在64以内
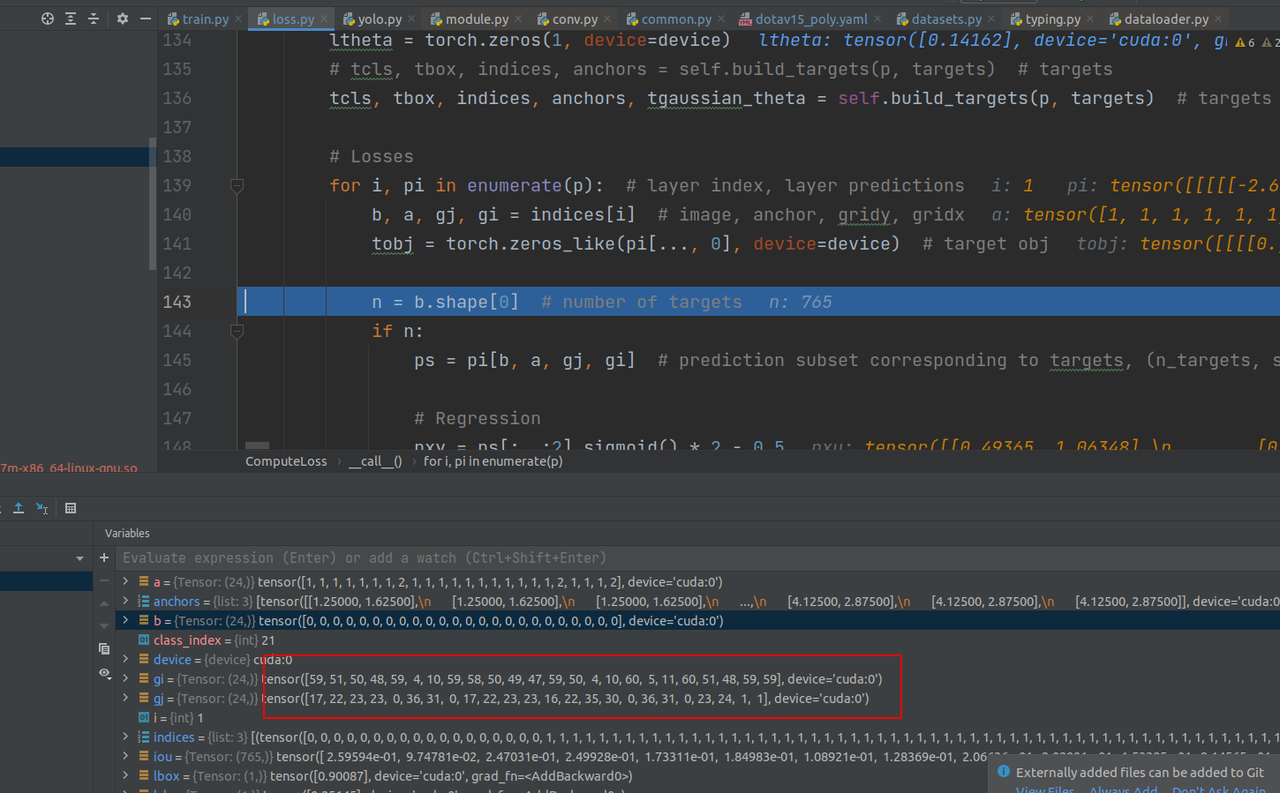
之后就是取出相应列的数据和targets数据作loss处理,没什么需要特别注意的。预测框部分采用的是CIOU,其他是BCEloss。
二、检测部分
需要注意的是,预测detect部分是相较于训练部分多了一些后处理,最主要的是NMS,训练的时候不需要NMS,pred网络出来的是什么就是什么,不需要改动,是要送去损失函数计算损失作反向传播以便下一次更好的推理。也因此,显然检测部分是不需要反向传播的。下面同样从数据的加载代码部分开始看:
1.模型和图片加载
加载模型和一些参数(权重文件的格式、预定的图片长宽,stride)stride相当与网络模型的输出的尺度和真实图片的尺度之间的比例,便于之后标记等,
加载test图片,共28张图片
同训练部分的加载图片(训练部分还有标签)过程的专有函数get_item一样,LoadStreams类的专有函数next:一般都是在这类专有函数中实现对数据的初步处理,然后送给网络。
最开始读取到的图像格式:分辨率+3通道
之后会进行一个resize,具体是到预定的宽高(1024*1024),当然,输入不一定长宽等长,取src_w/des_w,src_h/des_h中较小的比例进行缩小,并且补上一定黑边(yolov5特色)
这里在推理之前遍历dataset(过程中就是在调用上面的next专有函数),并进行归一化操作,以便送入网络。
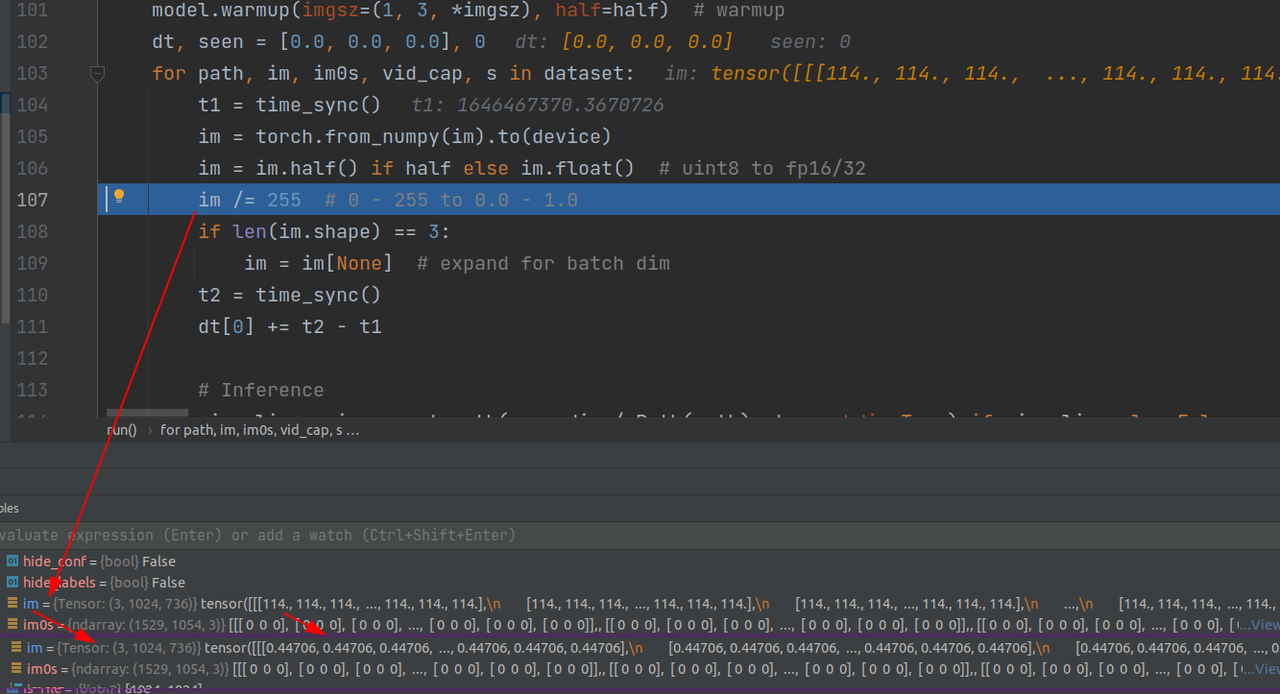
2.网络推理
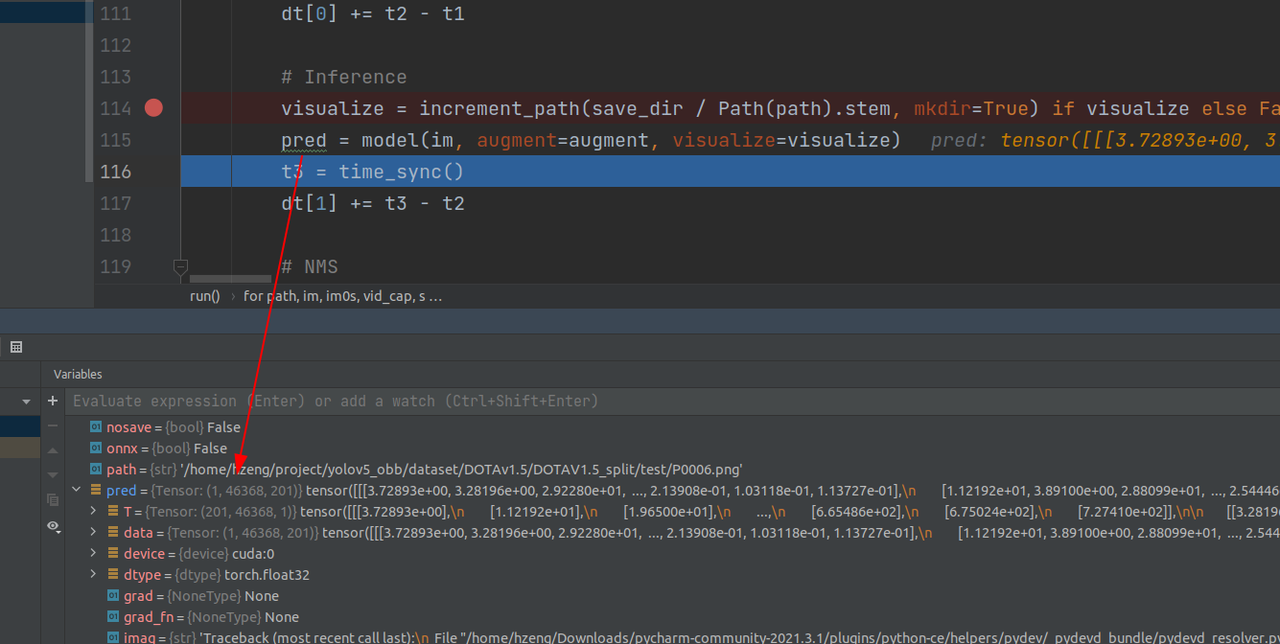
第一张图片推理结果:
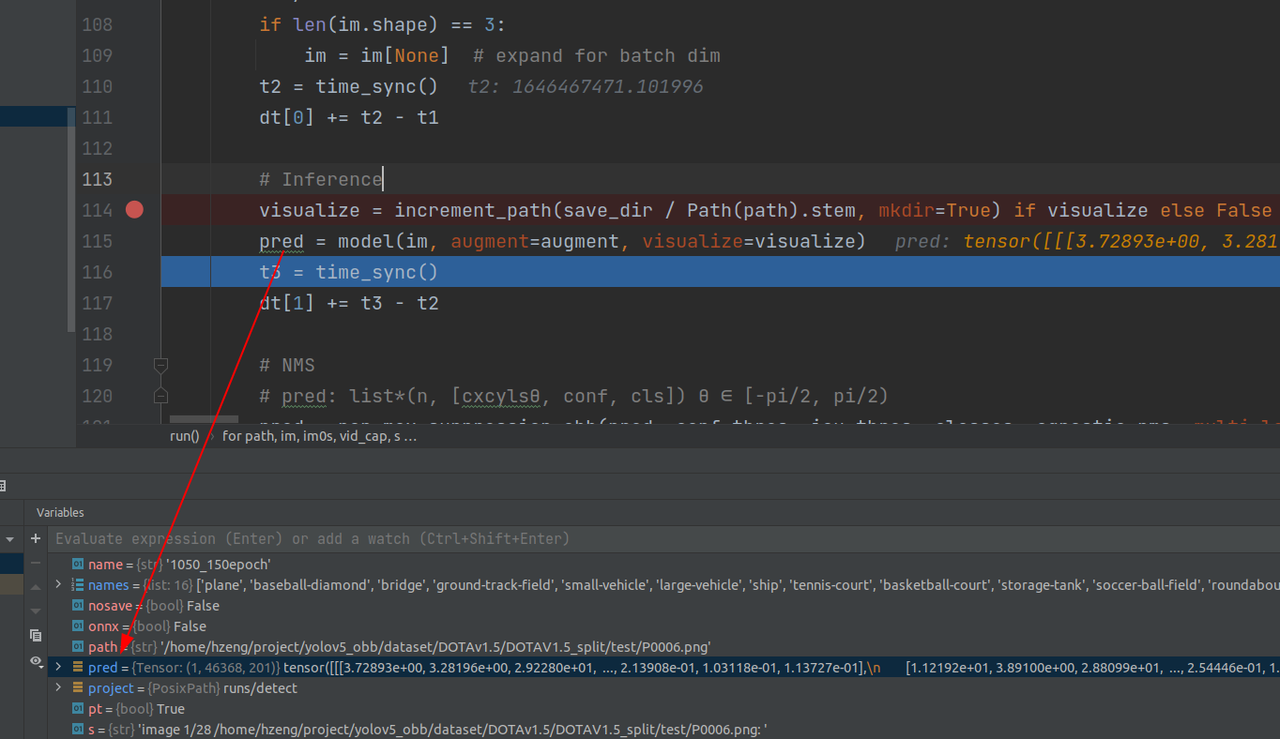
下面具体看一下推理过程细节(整体和训练的时候类似,有部分处理不同)
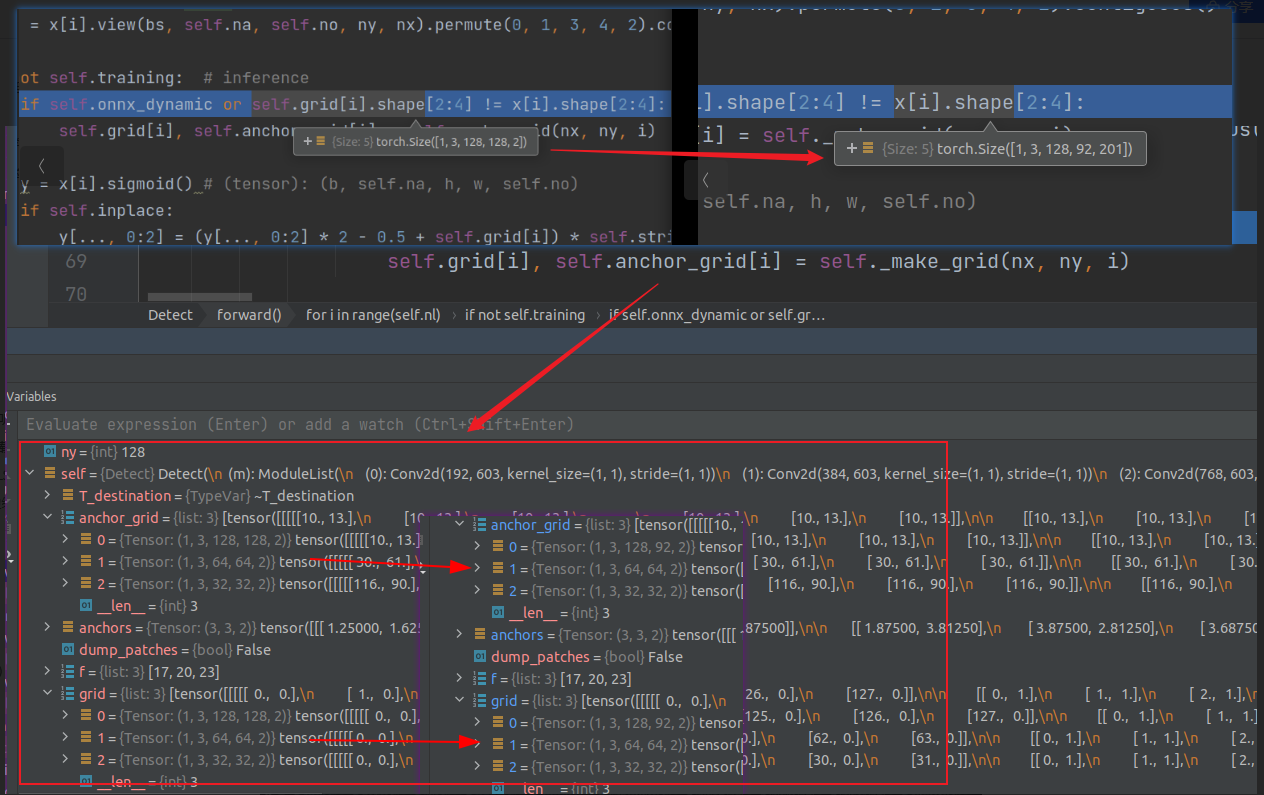
detect层之前,与预测过程同样的地方输出不同的是bs和最后一个图像宽高(输入不是1024*1024,所以不一样很正常)
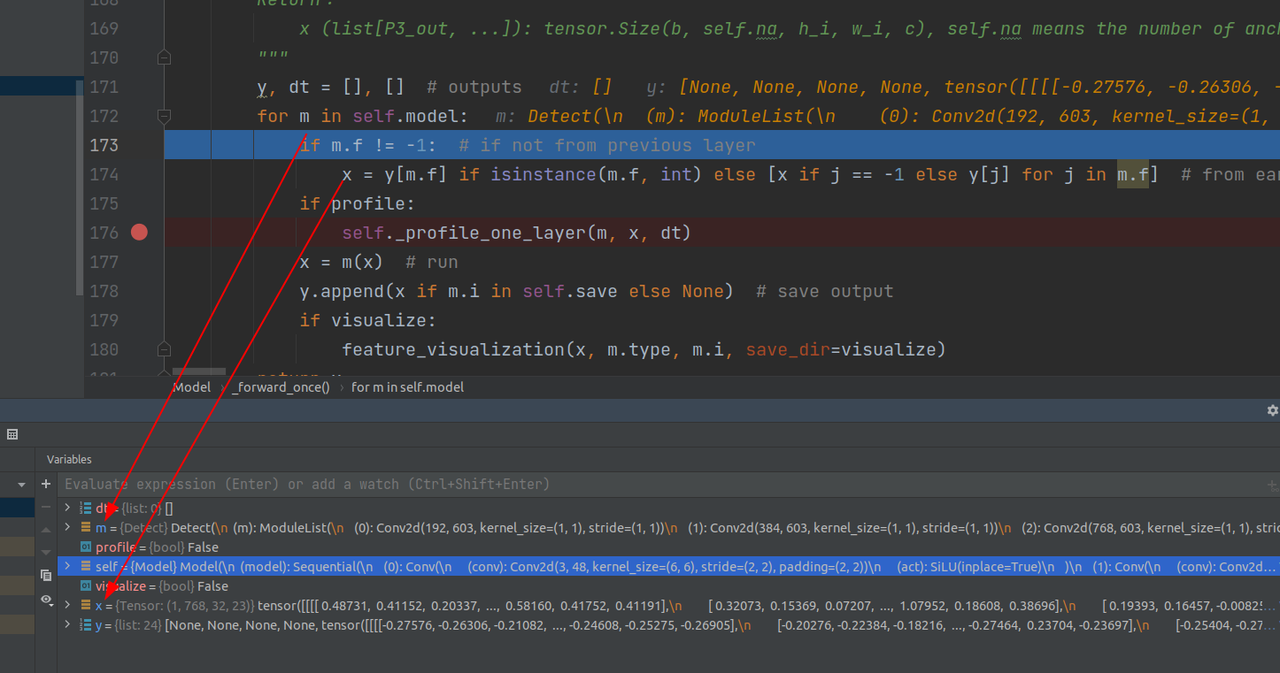
第一个尺度下生成128x92(原来是128)个grid,每个grid有201个预测通道
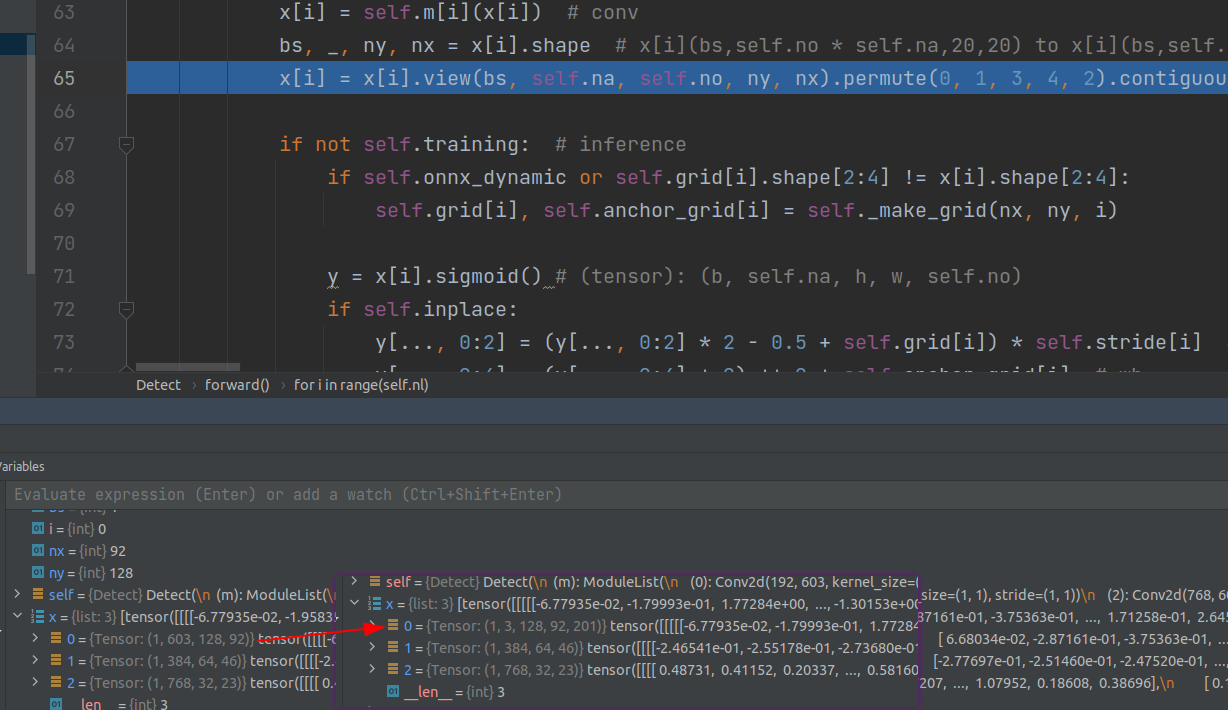
如果shape不一致,把self.grid,anchor等改成对应的
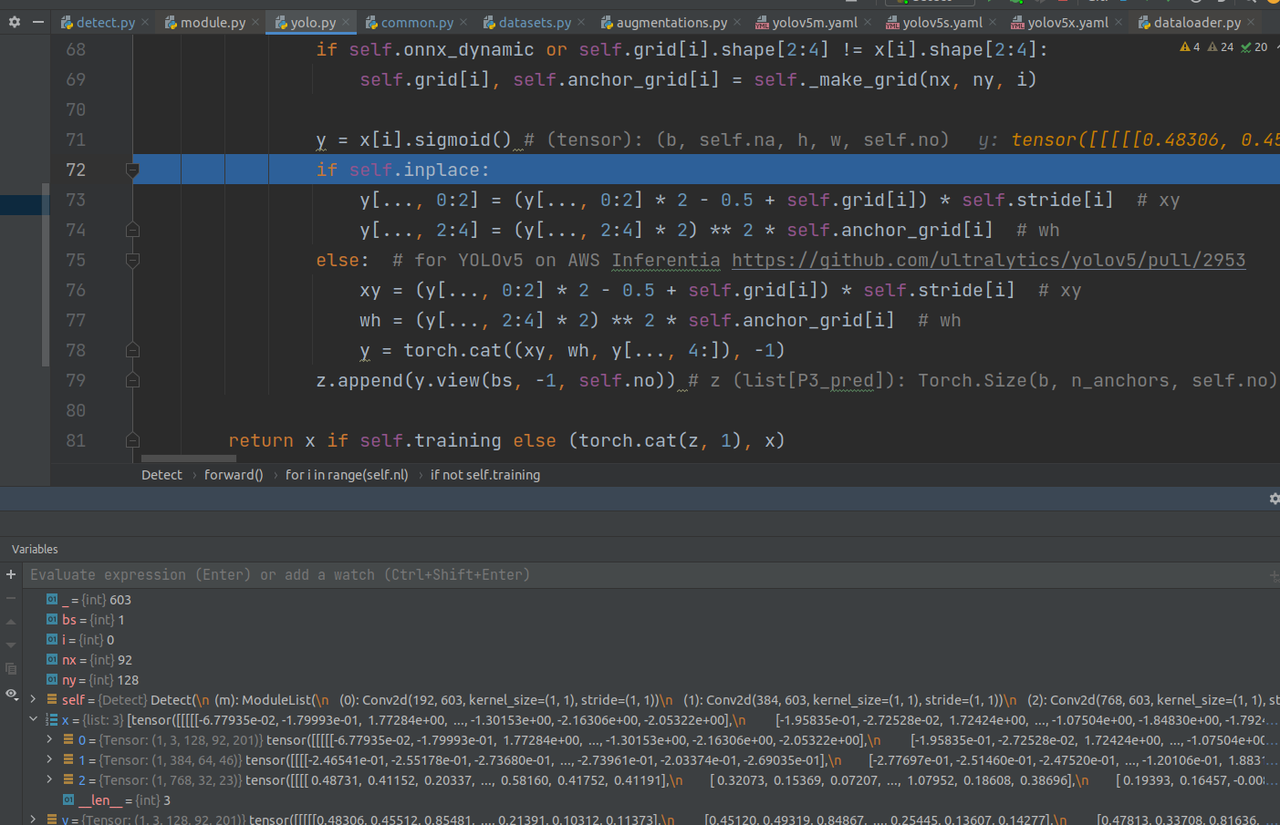
改成原图片尺度(这一部分在yolov5原理的时候有讲过,可以看之前的内容):
把除了最后一维度,其他维度打平,得到第一个尺度下的所有anchor输出
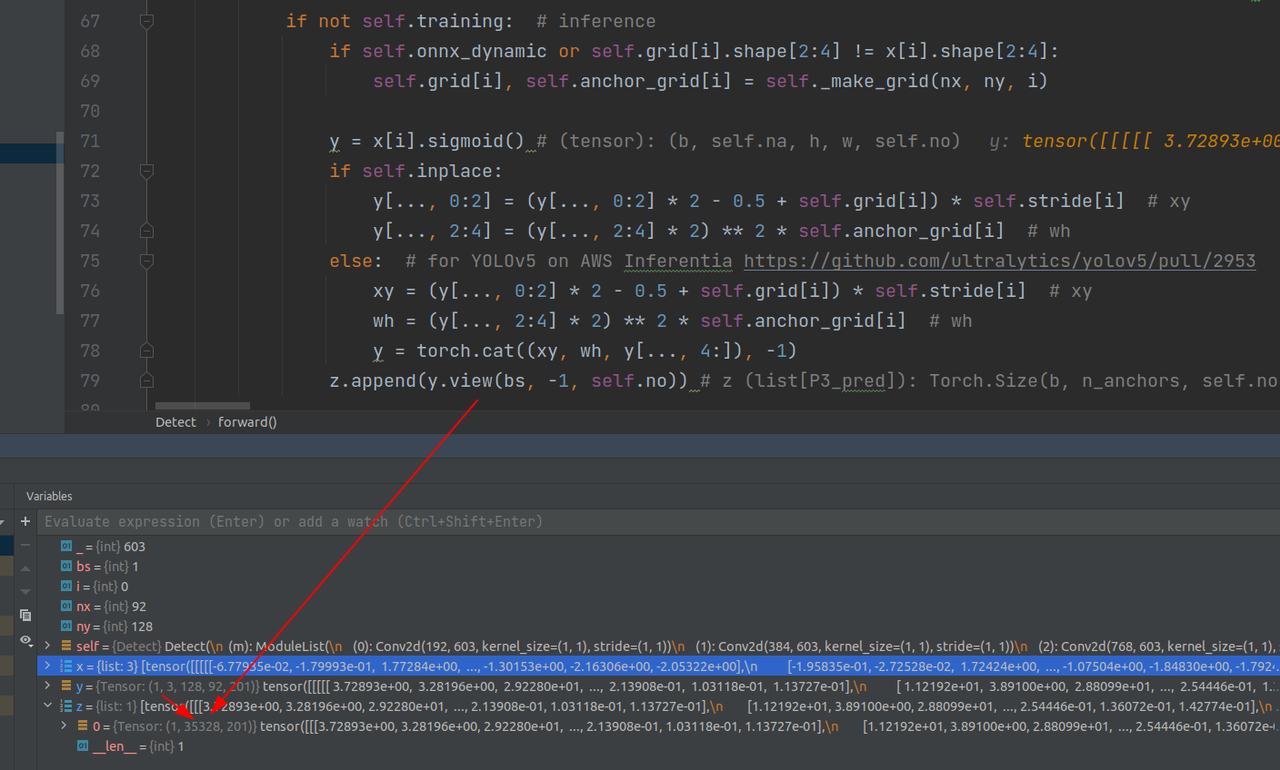
然后以此类推,遍历三个尺度,输出是按第一维把三个尺度的输出相加:
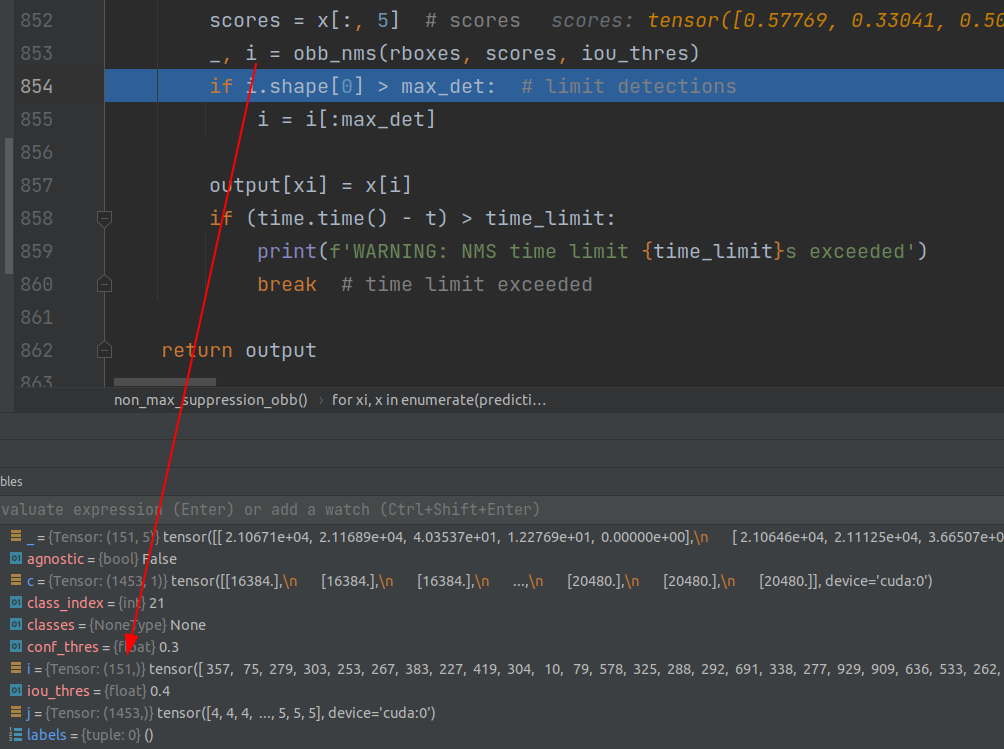
3.非极大值抑制
具体里面就是一系列处理,先通过预定的置信度筛选一部分,然后通过计算IOU,留下较大的。注意cls*obj的操作是在这里面完成的,最后返回符合条件,经过筛选的anchor的index。
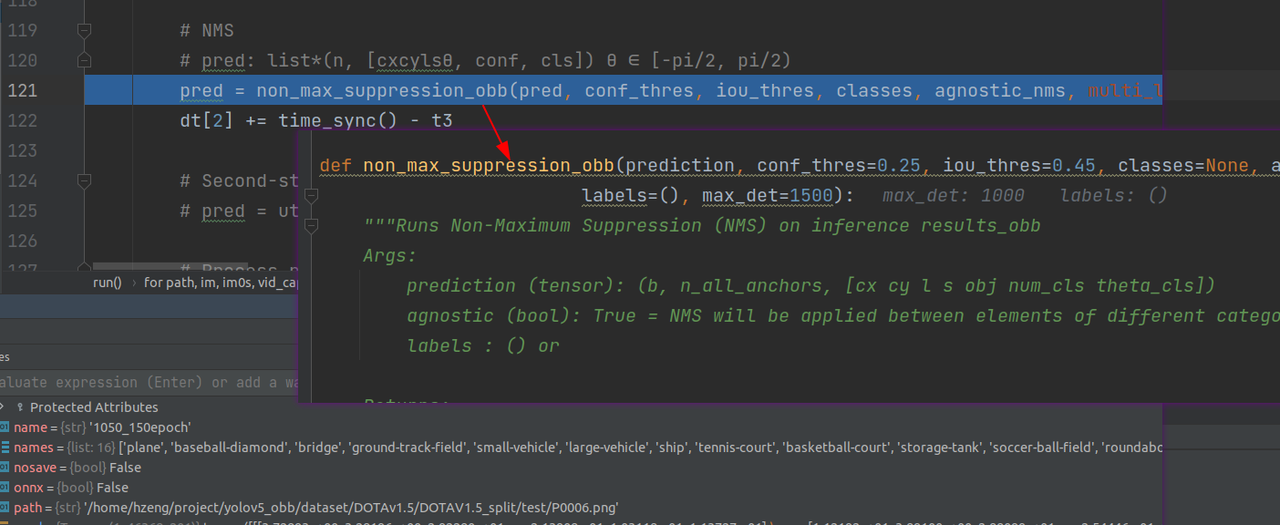
经过NMS只剩100多个有效输出
4.add poly
之后就是一些写检测出来的物体的label写到txt里,并且在图像中作标记的过程