yolov5目标检测原理探究(2)
本篇主要记录学习yolov5的原理,包括一些代码细节以及代码的复现。参考薛定谔的AI。
一、正样本采样细节
相关源代码位置:utils/loss.py/class ComputeLoss/def build_targets(self, p, targets)
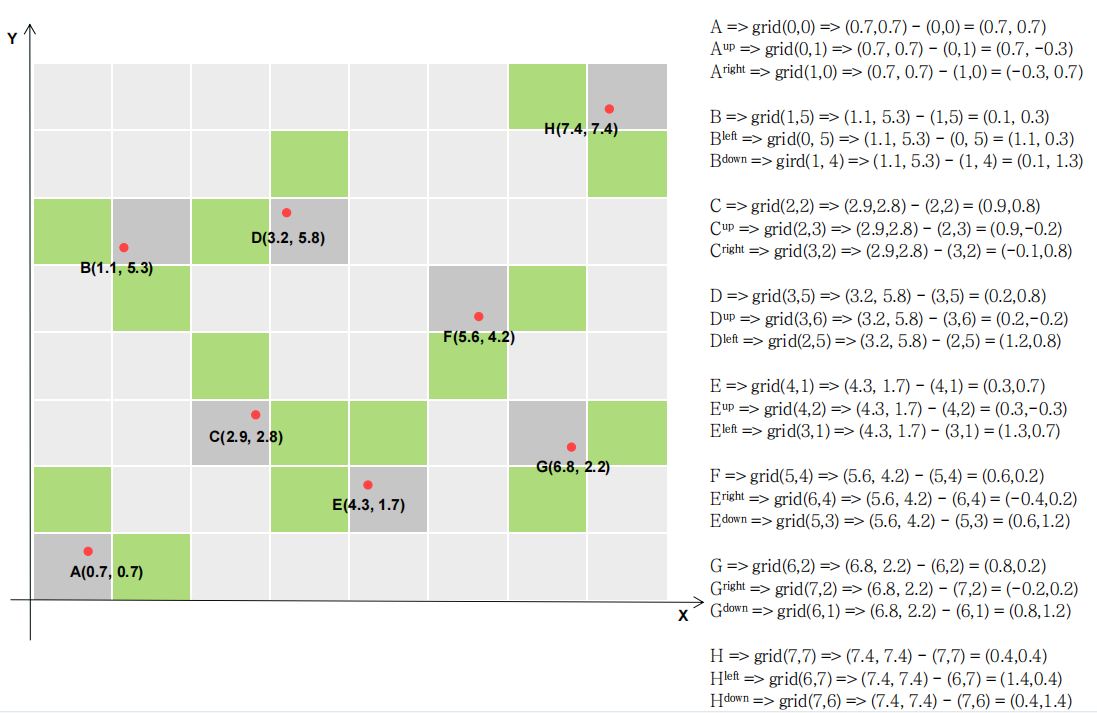
对于如图所示的8个目标边框的中心点:
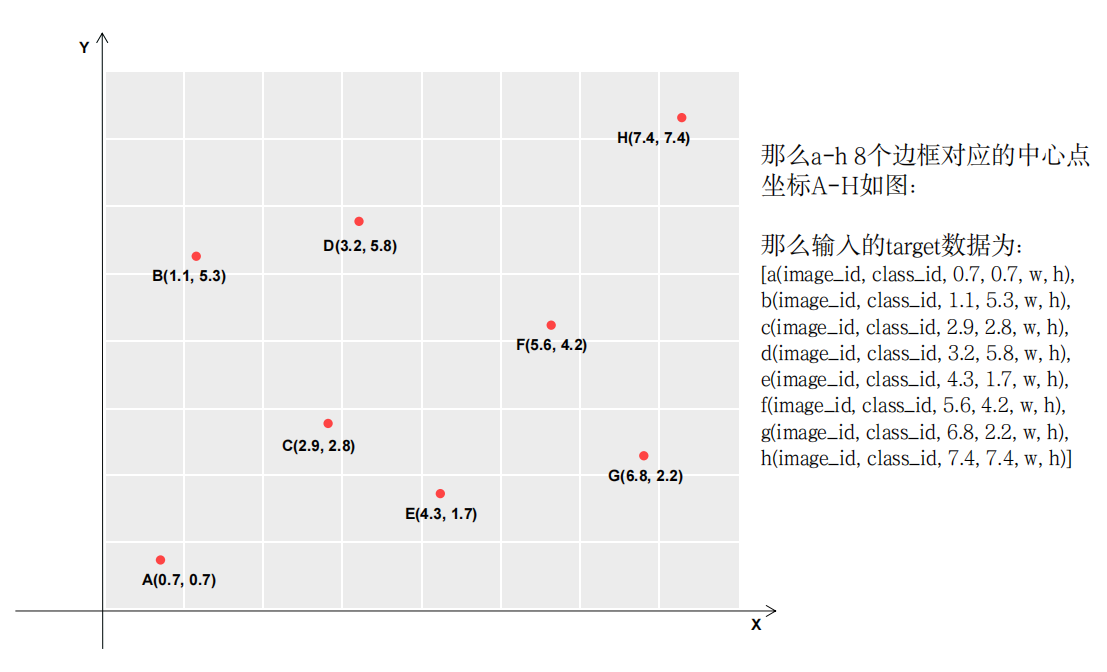
在代码中的如图位置会对目标边框的grid作正采样:
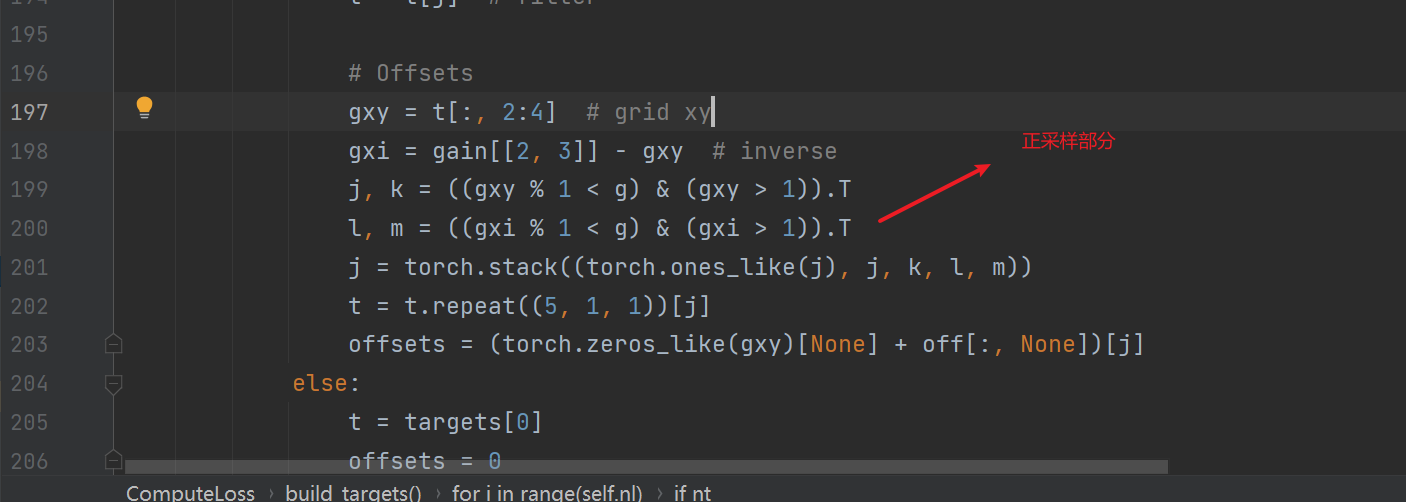
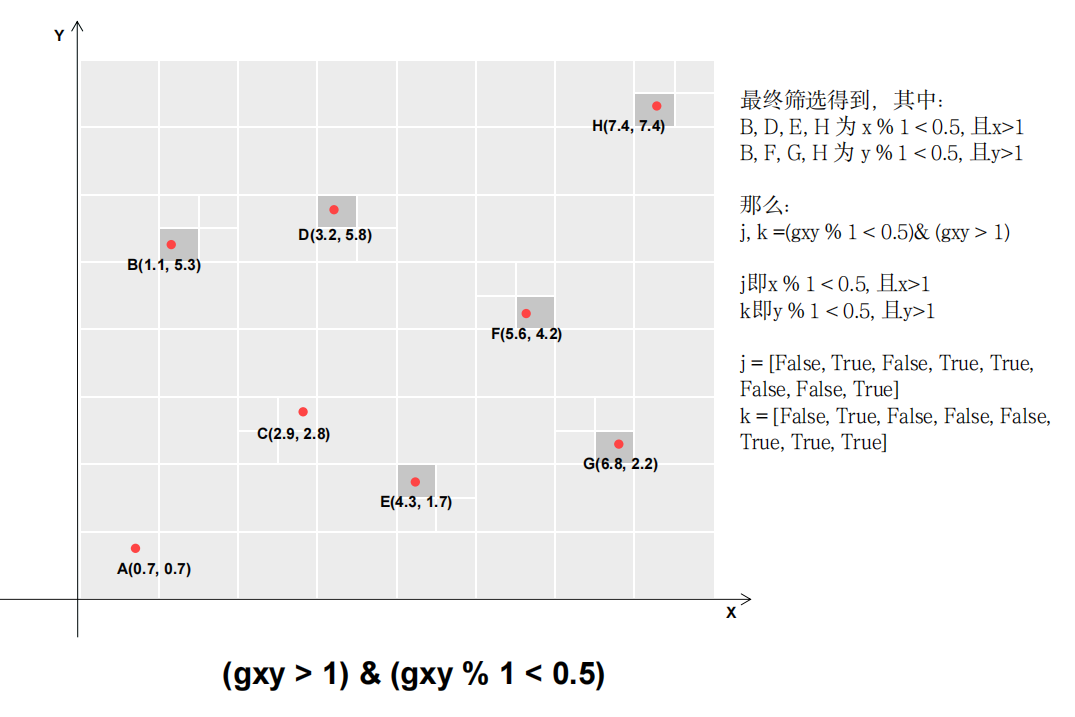
第一部分经过筛选之后得到如图结果(灰色),j,k是所得的布尔矩阵;l,m是以tensor右上角为原点之后作同样的筛选得到。
将所得点作对应的偏移:
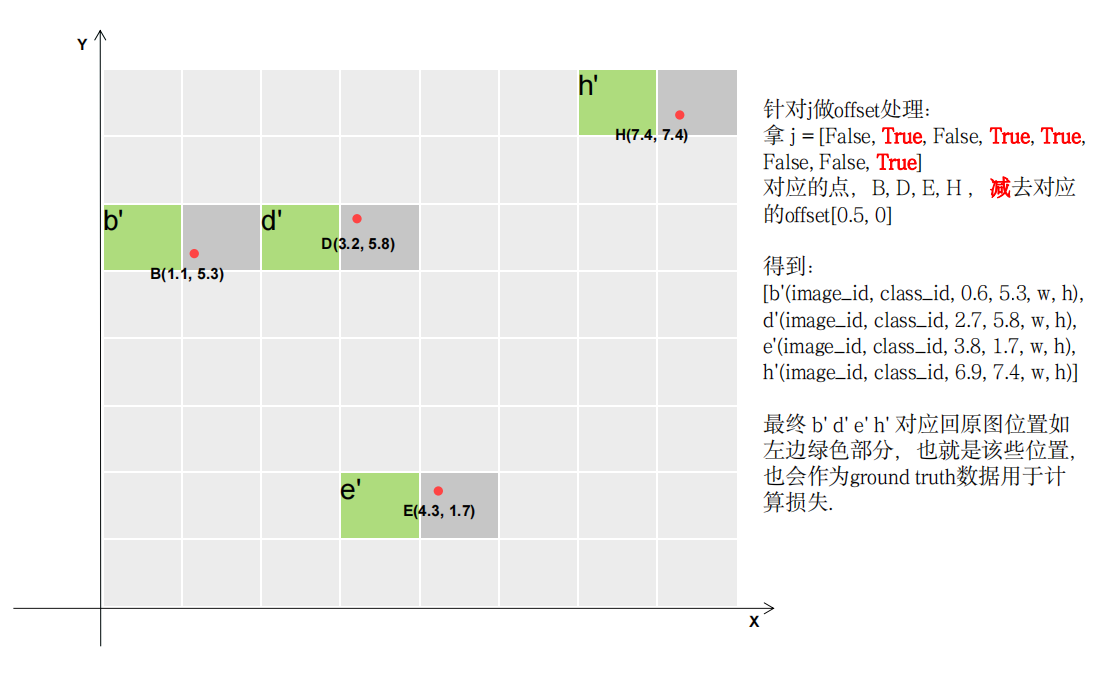
最终所得如图所示;其中深灰色即原ground truth对应边框数据,绿色为补充正样本边框数据。
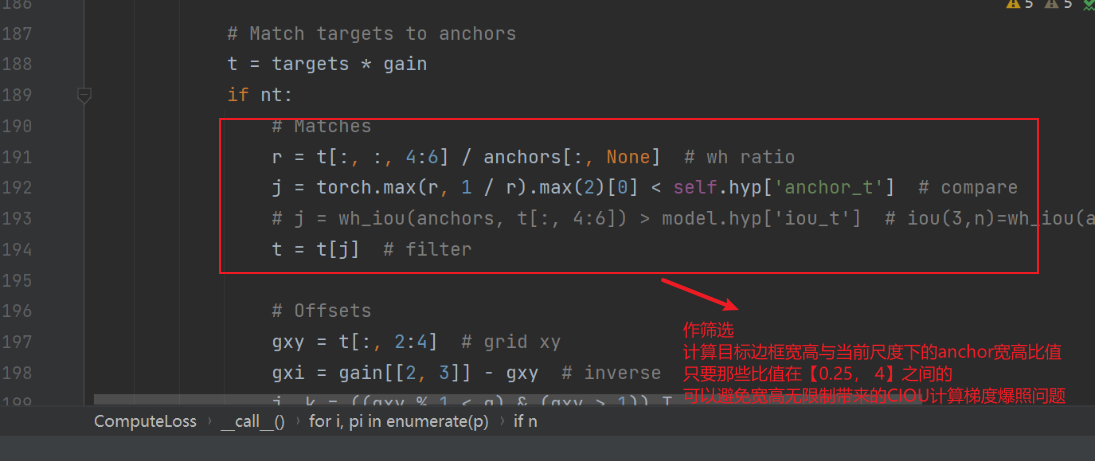
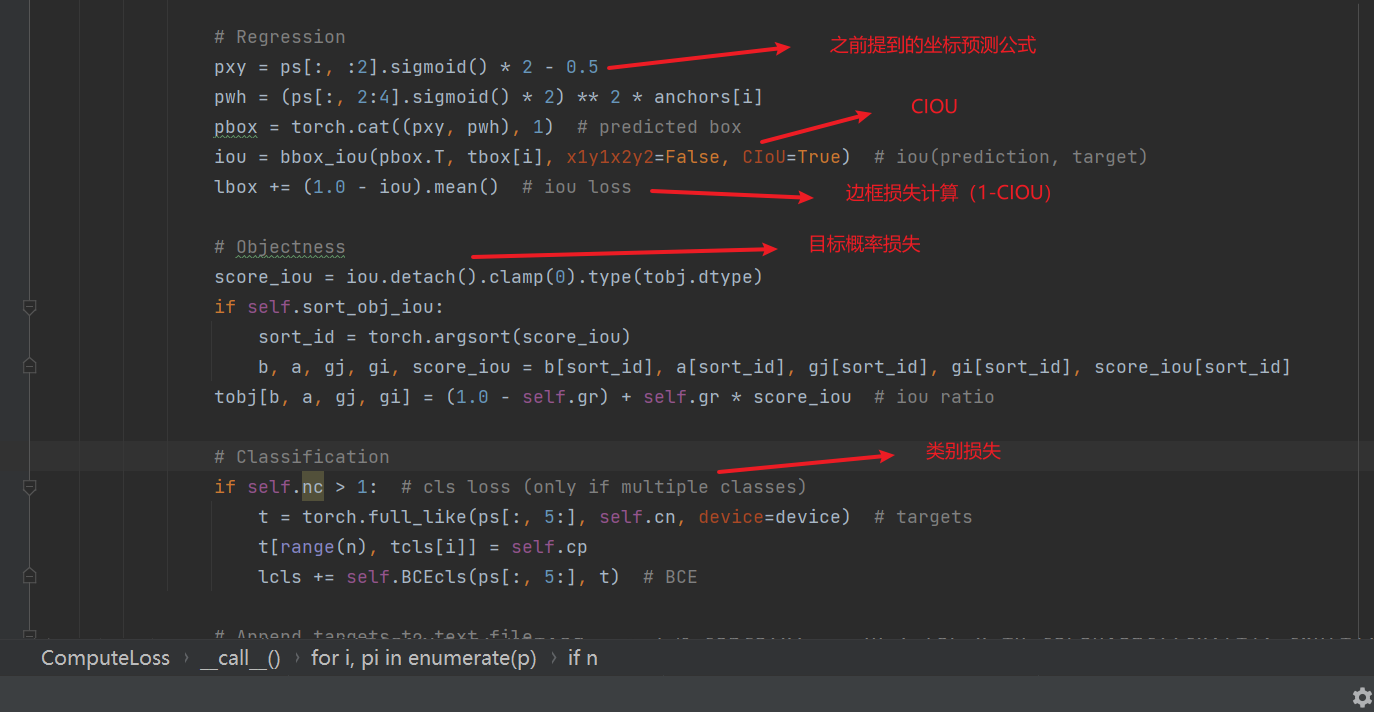
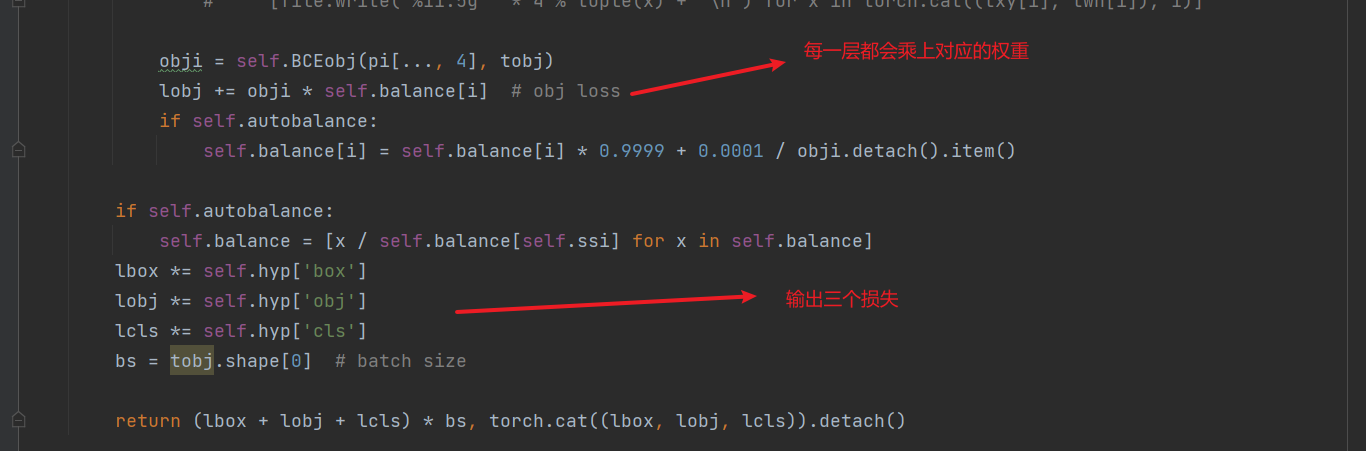
二、损失计算细节
相关源代码位置:utils/loss.py/class ComputeLoss
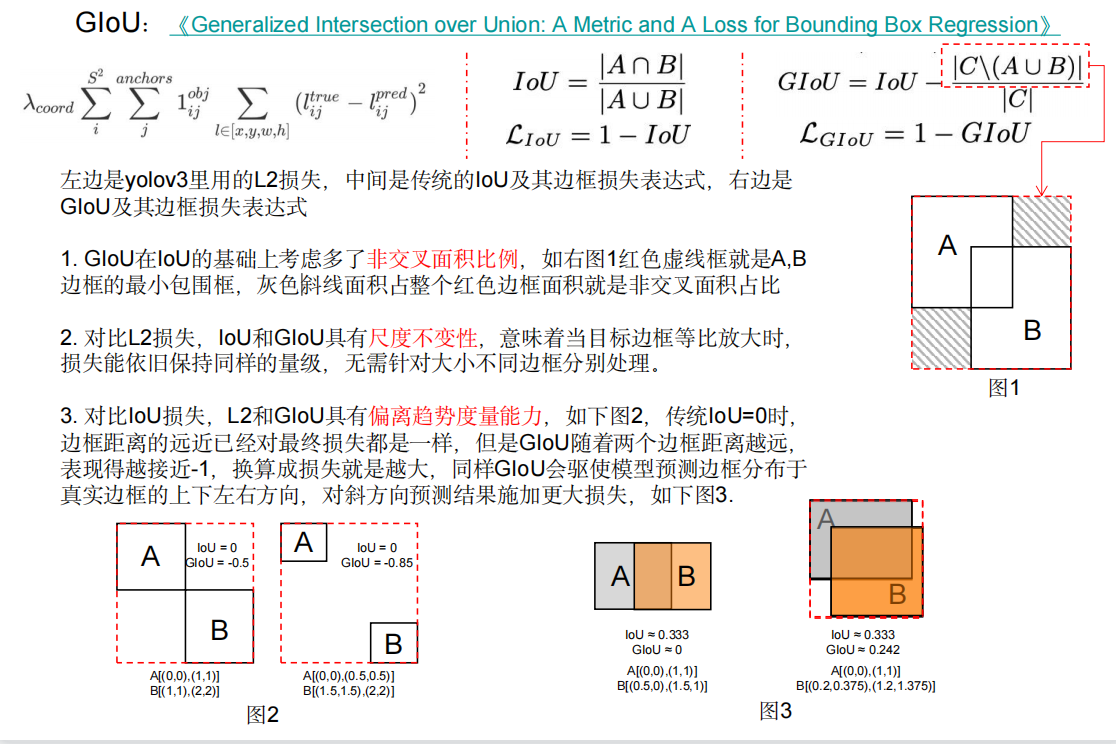
如图是GIOU,前两点比较好理解,第三点“偏离趋势度量能力”是左下角图2,如果此时采用传统IOU则两者数值都是0,则无法对训练过程作出很好的指导作用;当然当目标框和预测框处于水平或者垂直位置时,GIOU则退化成了传统的IOU,不具备优势,为了解决这一问题,提出DIOU:
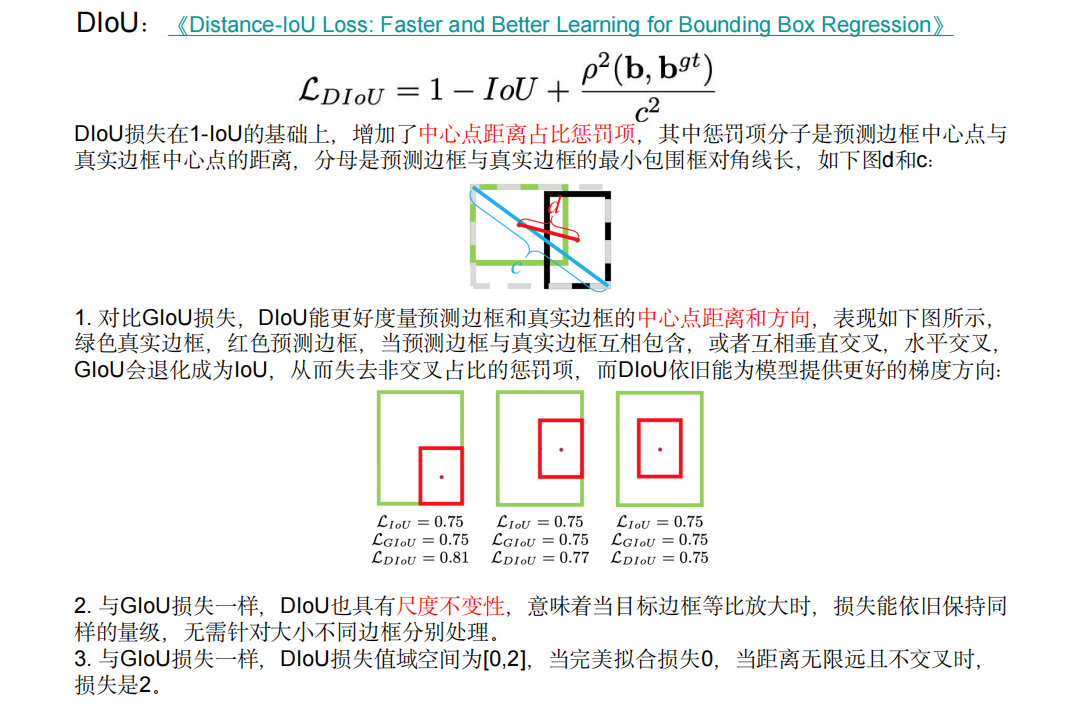
在最新的6.0版本的yolov5中,改为了最新的CIOU计算

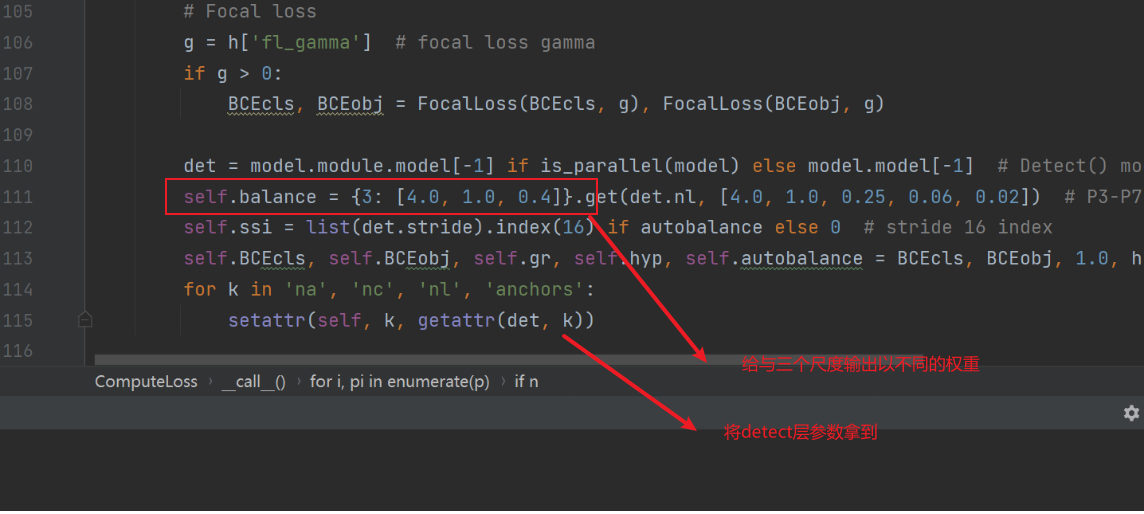
三、损失计算源码细节
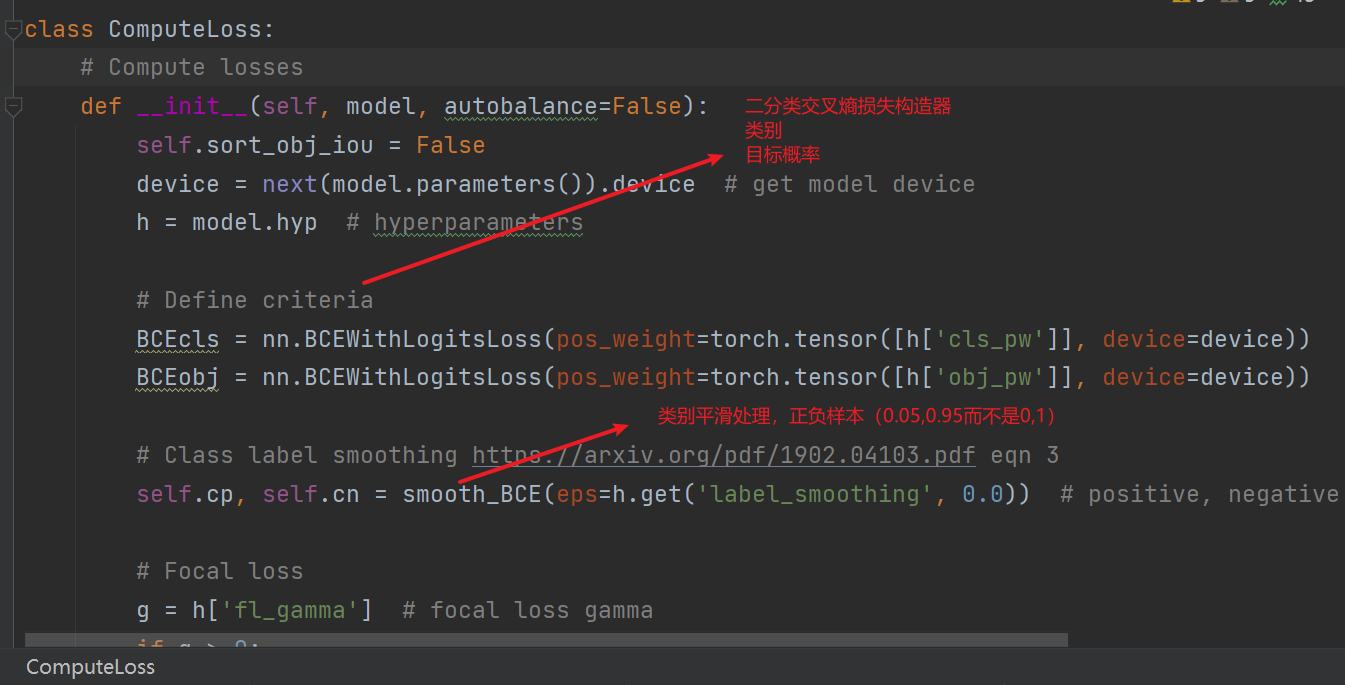
这里提一下focal_loss的作用(yolov5默认没有使用,可能是作者实验得到没有较大或者没有提升,但是我觉得这个理念还是挺好的)。focal_loss适用于正负样本比例失调的情况,比如一张图片里有10个正样本,90个负样本。那如果没有focal_loss的话,网络就会倾向于预测出90个负样本,毕竟正负样本权重一样,网络在tell出这90个样本不是我想要的会比tell出这10个样本是我想要的得到更多“奖励”。但是显然,我们想要的还是网络分辨出正样本。因此focal_loss所做的就是给与这少数的正样本更多的权重来让网络对正样本的预测倾向更高。