yolov5目标检测原理探究(1)
本篇主要记录学习yolov5w的原理,包括一些代码细节以及代码的复现。参考薛定谔的AI。
一、数据增强
源码中位置:train.py->create_dataloader->LoadImagesAndLabels;
参数配置:data/hyps/hyp.scratch.yaml
rectangular:同个batch里做rectangle宽高等比变换,加快训练
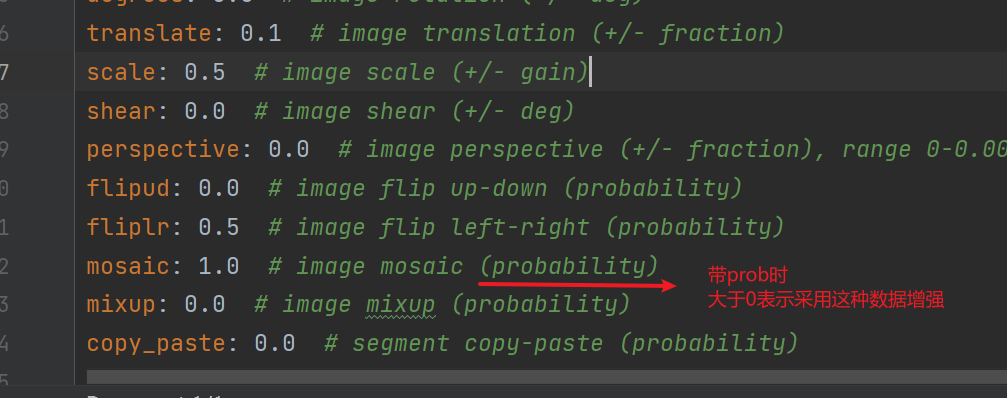
hsv h:0.015#image HSV-Hue augmentation(fraction),色调
hsv_s:0.7#image HSV-Saturation augmentation(fraction),饱和度
hsv_v:0.4#image HSV-Value augmentation(fraction),曝光度
degrees:0.0#image rotation(+/-deg),旋转
translate:0.1#image translation(+/-fraction),平移
scale:0.5#image scale(+/-gain),缩放
shear:0.0#image shear(+/-deg),错切/非垂直投影
perspective:0.0#image perspective(+/-fraction),range 0-0.001,透视变换
flipud:0.0#image flip up-down(probability),上下翻转
fliplr:0.5#image flip left-right(probability),左右翻转
mosaic:1.0#image mosaic(probability),4图拼接
mixup:0.0#image mixup(probability),图像互相融合
copy_paste:0.0#segment copy-paste(probability),分割填补
最后box坐标变换,segment坐标变换
1. rectangular
同个batch里做rectangle宽高等比变换,加快训练。使得每个batch的宽高一致,不同batch的宽高可以不一致,减少同一batch的图片中的“黑边”,同时这种客制化可以使得比如原来需要reshape到640x640的图片现在仅用reshape到540x450。这样输入的图片的尺寸减小,数据量大起来的话会减少非常可观的计算量。
源码位置:utils/datasets.py Rectangular Training
2. 旋转、偏移、错切等
这几个操作都是把原图乘上一个变换矩阵,不同在于矩阵中参数设置。

需要注意的是,所有的数据增强的操作对图片的操作都要在之后对相应标签也做操作。这部分源码参考:utils/augmentations.py
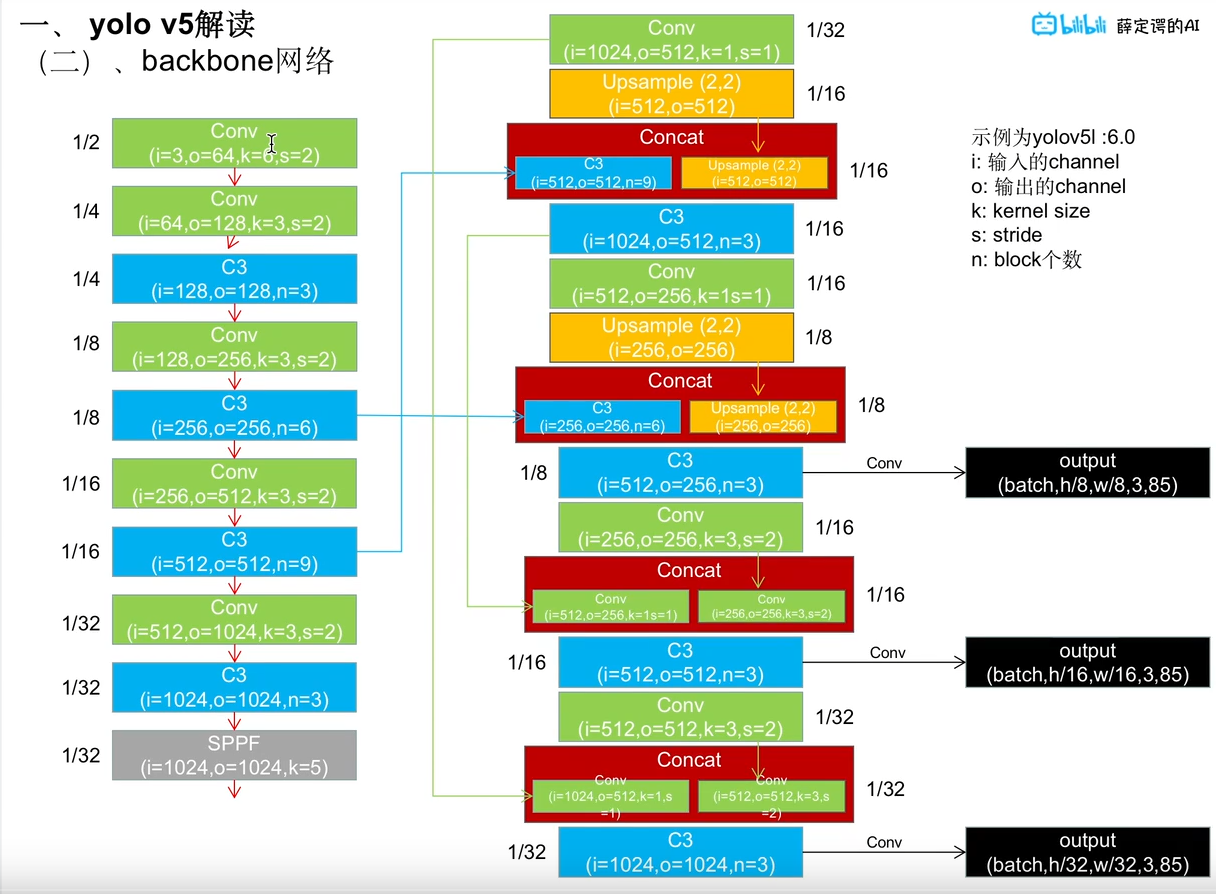
二、backbone网络细节
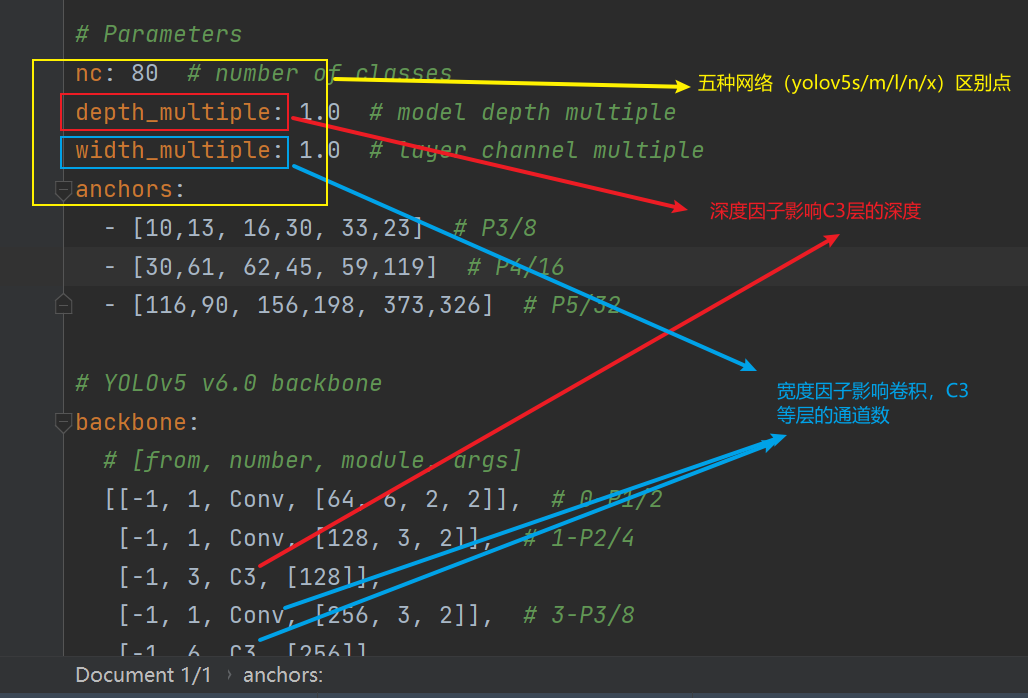
可参考源码中models/xxx.yaml文件。
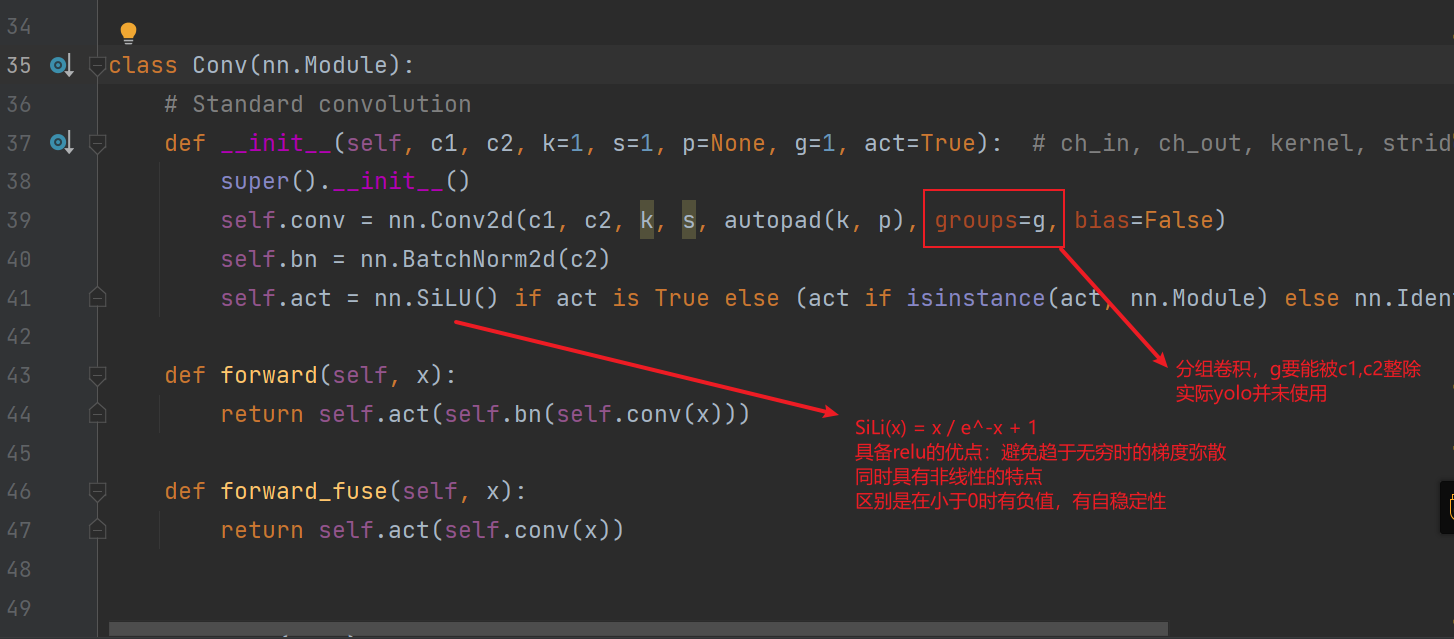
1.Conv层
2.C3层
相比于BottleneckCSP的4个卷积少了一个,所以称为c3
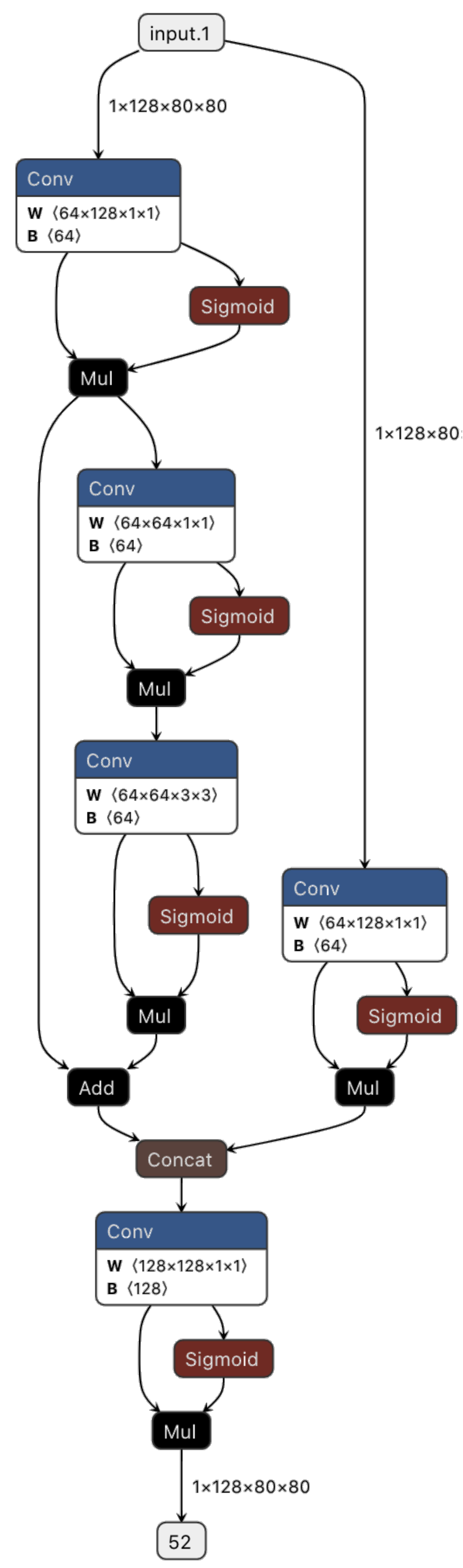
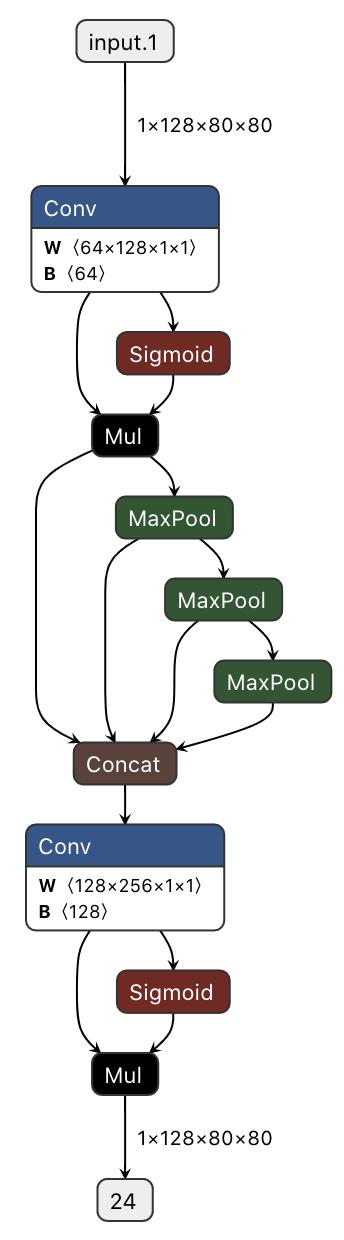
3.SPPF层
三、backbone网络源码解析
四、边框预测细节

在yolov3/2中,对正样本的处理是一个grid最多产生一个正样本,或者说如果某个区域存在一个目标,那么只有该区域中心点所落在的grid是正样本。这么做的坏处了正负样本的比例失衡,影响训练过程。yolov5把那个grid上下左右的grid都采样使用,因此范围用(0,1)无法表示。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 不听话的兔子君!