yolov3目标检测原理探究
本篇主要记录学习yolov3的原理,主要是对yolov3论文的精读。参考:同济子豪兄
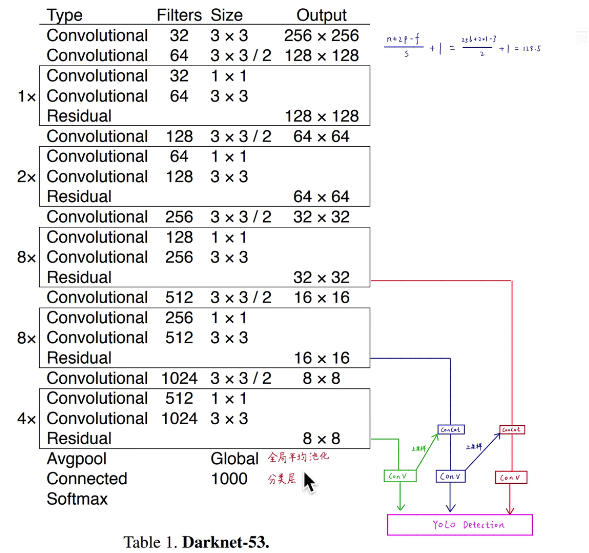
一、骨干网络 DarkNet53
yolov3的骨干网络(backbone)从yolov2的darknet19改成了darknet53,如图:前面的1x/2x代表重复这个block。输入可以是不同尺度的图像,但是必须是32的倍数,因为最后会对feature map进行32,16和8的下采样。然后输送给检测部分。
二、网络结构
255 = 3 x 85(80 + 5)
每个grid cell有三个anchor;
每个anchor有(x, y, w, h, objectiveness)五个基本参数,加上coco数据集的80个类别的条件概率信息(在假设这个框的是物体的情况下,它是猫/狗/...的概率)。
而前面则是grid cell的数量,13x13个,26x26个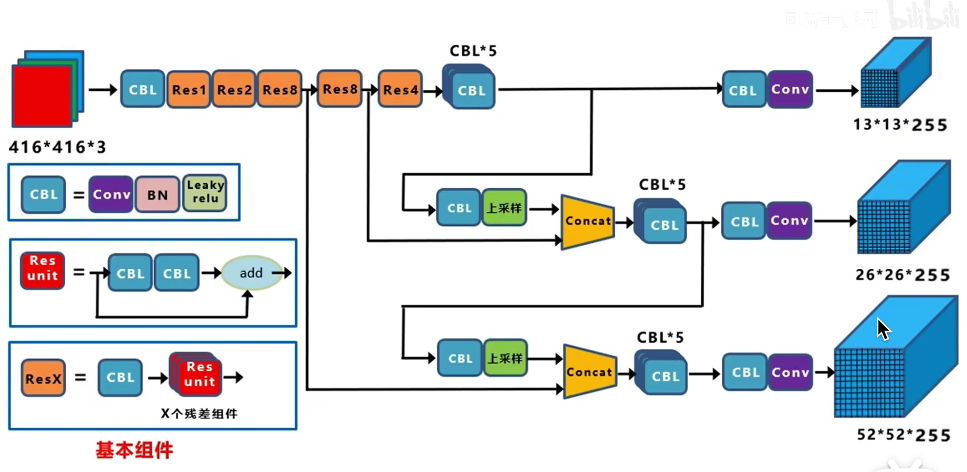
在yolov3中输出是三个尺度的,而显然,某个物体可能同时落在三个尺度的三个grid cell所产生的9个anchor,那此时,将由与ground truth的IOU最大的anchor去作拟合,这个anchor也是唯一的正样本。
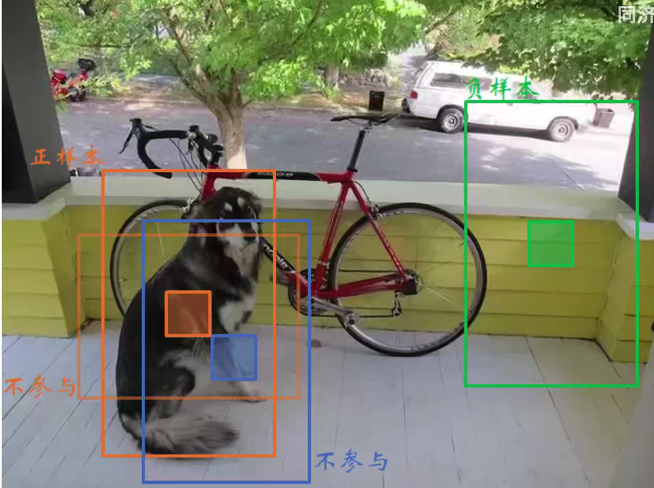
三、损失函数
yolov3中,以阈值为区分,大于某个阈值的所有的anchor中与ground truth的IOU最大的那个作为正样本,其余不参与;小于某个阈值的则直接视为负样本。
yolov3的损失函数分为3部分
1. 正样本坐标的损失
2. 正样本的置信度和类别
3. 负样本的置信度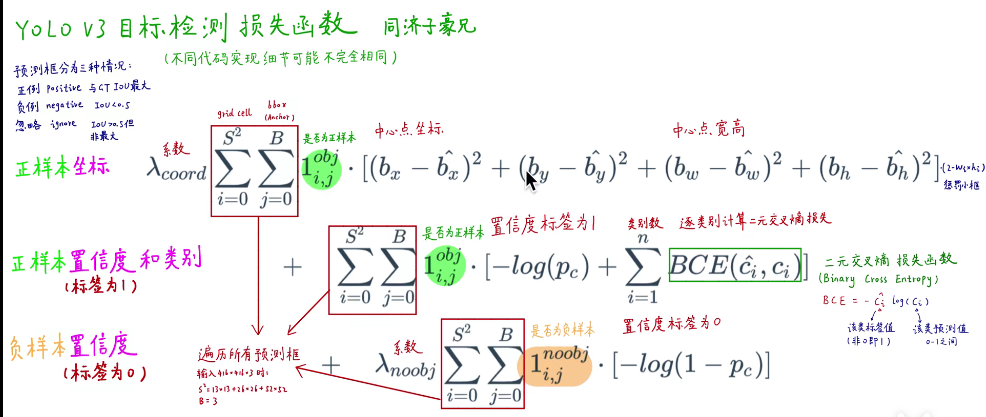
四、yolov3论文精读
前面也提到了。yolov3会把图像分成3个尺度,每个尺度的每一个grid cell会产生3个anchor,最后会选择这9个anchor中IOU最大的作为正样本,同时,把他的置信度设置为1,这一点是yolov3开始,因为在此前是把IOU作为置信度,但是实际效果可能是这个置信度最大才是0.7,显然,这样训练时的”激励“效果就不如把置信度设置为0要好,毕竟,这个anchor现在是唯一的正样本。另一方面,coco中的小目标IOU对像素偏移非常敏感,用IOU直接作为置信度可能达不到理想的效果。

关于分类,yolov3也不再使用softmax,而是简单的对每一种类别进行二分类,因此,所有的概率和也不一定是1.

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 不听话的兔子君!